Backstory: All of my family’s movies and TV shows are streamed to our Apple TVs and my kids iPads using Plex (unless they come from one of the streaming services). If you have young children, it is not acceptable for the internet to blip out, slow down, or for a favorite movie to be pulled due to licensing issues between international billionaires, so having a locally, always available copy is critical.
My setup has stayed pretty consistent the last few years. I keep Plex running on my iMac Pro, which is great because it’s always awake and online. Even better, it can handle multiple transcoding sessions without breaking a sweat. So even if both my kids are watching something on their devices and my wife on the TV, I can be working in Xcode and not even notice the iMac doing anything different. It works so well, in fact, that I even invited our parents and siblings to our Plex account so they can watch our library remotely.
The only downside to this setup is that all this content is stored on an 8TB external drive hanging off the back of the iMac. And that’s fine, except…it’s loud. We’re talking late 90s beige tower clicking hard drive loud. The noise hasn’t been an issue previously because my kids’ movie watching and my time at my desk only overlapped on the weekends. But now that schools are closed and the world is working from home, I can hear it chewing through data all damn day.
We don’t have a NAS and I don’t really want to buy or deal with one. So, I bought my first Raspberry Pi, installed Samba, and moved it and the noisy drive inside a bookcase next to the router. And because it’s hardwired and not going over wifi, LAN bandwidth isn’t an issue as the videos round trip from Plex on my iMac, to the Pi, then back to Plex, then to whatever device is being watched. Yeeesh.
But all that video and music being available to Plex requires macOS not lose the connection to the file server. You can make a share automatically mount at startup by dragging it to your user’s login items in System Preferences, but that doesn’t help if the connection randomly drops.
I found a few 3rd party solutions to keep network shares mounted – I paid for and gave this one a try. It’s really nice! But at the end of the day that’s just one more app running in the background I didn’t want – two, if you count the extra helper app you have to install so it can work around macOS’s sandboxing restrictions. (Not the developer’s fault.)
That checks to see if the share is mounted (if the directory for it exists) and, if not, mounts it.
Throw that in a cron job every minute or so and ?. Here’s a quick recording of me manually ejecting the share and then having it immediately come back online:
For me, though, I transitioned to running all of my background jobs using launchd instead of cron a few years ago. It would be way too complicated to maintain all those .plists by hand, so I use LaunchControl to do it for me instead. Seriously, it’s fantastic. Go buy it.
One day I will get around to either releasing or open sourcing the dozen or so bespoke, one-off Mac apps I’ve built just for myself.
Today is not that day.
The reason for that is because I really do have a backlog of random, one-off Mac apps that I’ve built over the years just for myself. Most of them are small utilities that do a very specific thing that make my life easier. While others are more ambitious. In any case, it’s another week, we’re all stuck inside, so here’s another app that I built two years ago.
It’s a dead-simple and slightly dumb Mac menu bar app for Spotify – there are many like it, but this one is mine. Here’s why.
I’ve probably tried a dozen open source, free, and/or inexpensive Spotify “mini players” – many of them on the Mac App Store. But I’m picky, and none of them behaved exactly the way I wanted. Here’s what I’m after…
I hardly ever listen to my music with Spotify or any other streaming service. The music I care about – my collection of 40,000 mp3s dating back to CDs I ripped in high school and have since carried across twenty different computers – are all stored on a file server at home and available wherever I am via Plex or Prism. If I’m listening to my music, I know exactly what’s playing at any given moment. I’m sure you do, too. There’s no surprises.
But I use Spotify, and previously Rdio and Apple Music, for discovery. I’m constantly streaming playlists of recommended artists and albums I’ve never heard before – always listening for something new.
Given that finding something new and amazing is my number one reason for using any streaming service, I’m constantly pausing what I’m doing and breaking my flow to quickly glance and see what I’m listening to. And nowadays there is. So. Much. Friction. just to see what is currently playing.
Every music service uses their own awful website disguised as a desktop app. Even on my iMac Pro – and especially on an underpowered laptop – checking the current track feels equivalent to launching Creative Suite in the 2000s. I just want to see the song title – not launch a entire instance of Chromium.
So, for a long time I used various 3rd party apps to keep a floating window of artwork on my desktop. Some were really nice. But they were always a pain in the ass to reveal. I’d typically have to ⌘-tab through twenty open apps just to bring it to the front. And it always bothered my obsessive compulsive nature having an extra window cluttering up my screen when I prefer to only have windows belonging to the current task visible. (Yes, I’m crazy.)
Anyway, like any good developer who practices Hate Driven Development, I decided to build a Spotify mini player that behaves exactly how I want. Here’s a screenshot:
Everything I want to know – right there in the menu bar…
Artist
Album title
Song title
Yes, the text is nearly incomprehensibly tiny, but I dig it. It crams all the pertinent info into a small space and it makes me happy because I can glance up the menu bar at any time no matter what I’m doing or what context I’m in.
But if that font makes your eyes bleed (I get it), you can add/remove song items in any combination. So, just the artist and album names?
Or just the song title?
Spotish does some other nice things, too, besides just displaying the song info. The background animates to show the song’s progress…
Click to view the album artwork…
Clicking the image will launch Spotify and display the song in the context of its album.
Or, you can control-click (right click) the menu bar item to play / pause Spotify directly.
And, of course, there’s a few preferences to tweak to your liking…
But my favorite feature? The one that really makes my geek gears turn? Spotish integrates with Drafts.app.
Shift-click on the menu bar item and Spotish will create a new draft in Drafts with all of the current song’s info as well as a shareable link to its page on spotify.com
It’s a fast and completely frictionless way for me to bookmark or remember songs I want to take a closer look at later. (Yes, Spotify lets you ❤️ songs. And you could always add it to a “Listen To” playlist. But this is faster for me and fits my personal workflow better as I often want to do something with the song’s info as opposed to merely just liking it.)
So, that’s Spotish. I love having it in my menu bar. Maybe you will, too?
Every task management app has a feature that will let you postpone, delay, or snooze a task. You can tell them to push a todo item out by a day or a week, etc. But I like to think Three Things is smarter than that. It’s designed to be flexible and forgiving – pragmatic and realistic. When you defer a task, it won’t accidentally reschedule it for a day that’s already overflowing with commitments. It literally will not allow you to schedule more than three tasks per day.
One day I will get around to either releasing or open sourcing the dozen or so bespoke, one-off Mac apps I’ve built just for myself.
Today is not that day.
That’s where Rebudget came from. It’s an app I built just for myself, and then decided to release because I thought others might find it helpful.
The app I’m announcing today is in the same vein: a one-trick pony that serves a very specific purpose – it fills a need I personally have. So I built it, have been using it, and I’m now putting it out there.
Never underestimate the healing power of taking even one small step when you’re under that terrible weight of “too many tasks to handle.”
Let me be clear: this does not replace my beloved OmniFocus or Fantastical. That’s not its purpose. Three Things supplements those other apps. It’s what I use to plan my days and weeks at a level above the nitty gritty details that OmniFocus handles, but not quite as high up as what you might call your “life goals”.
My System
Feel free to skip ahead to the details about the app below, but it’ll probably make more sense if you stick with me just a bit longer so I can explain how I personally get things done and how Three Things helps.
Every day, amidst the usual responsibilities of two young kids, chores at home, finding five minutes to actually talk to my wife, bug reports and dev work from my day job, etc., my goal is to accomplish three things. Sometimes even just two. Maybe.
They don’t have to be anything seriously big, time consuming, or significant. Just three things that move forward whatever current projects or goals I’m focusing on. Often times they’ll be related to my software business or other freelance work. Other times it might be an errand that I’ve been putting off or some skunkworks development I want to do for my day job.
But if I can go to bed at night knowing that along with the chaos of a career, family, and every day life, I did something else, I’ll feel good.
So, I plan out my days – usually seven to ten days in advance – each with the two or three tasks I hope to accomplish. Basically, this splits each day into thirds. I try to do one thing in the morning, another around lunch, and one more after work. Often times, though, I’ll get busy and wind up taking care of stuff after everyone else has gone to bed.
The point of this system isn’t to be rigid. It’s not a todo list with hard deadlines. More than anything else it’s flexible and forgiving. It lets me look ahead into the near future and see what’s on the horizon, and, more importantly, know if I’m over committed. Knowing that I can do at most three things each day – usually just two – and having everything stacked up in front of me day-by-day is illuminating.
David Sparks has writtenextensivelyabouthis move to block (née, hyper) scheduling. This is a similar system – my own take on it that just happens to use a bespoke Mac (and iOS?) app molded around my workflow. Oh, and to steal a quote from David just so we’re all on the same page about this type of system:
I’ve received lots of affirmation from readers that have been doing this in some form or another for years and ask me, in one way or another, “What took you so long?” Some folks call it block scheduling, others call it fancier things like value-based time management. I’m certainly not the first guy to this party, and I find that comforting.
Three Things.app
So what is Three Things? Well, it’s a calendar that lets you schedule tasks on each day. It’s meant to be excruciatingly pragmatic and realistic about how life works. (At least my life.) It literally will not allow you to schedule more than three tasks per day.
And that’s very important and also the point of this system. I already have over a decade’s worth of habits, workflows, and actions in OmniFocus using various combinations of defer and due dates to keep me on track. Three Things lets me plan and schedule my near-term road ahead and enforces restrictions that make sure I don’t overbook myself. And that’s why it’s pragmatic. I built it knowing that even on my best of days, I’m at most going to have the time and energy to do three things on top of the rest of life’s commitments.
I also intentionally described the app as realistic. That’s the other key feature of the app. I know (and Three Things knows) that life happens. That shit happens. Some tasks will take longer than I expect. And some days a fire will break out at work and I’ll have time for nothing else. And yet other days I just won’t be feeling it and would rather take a mental vacation. So, I do.
On those days, Three Things has your back because of two magical menu items:
If a task just didn’t get done or you skipped it – hit ⌘D and Three Things will automatically move it to your next available slot in the future.
Every task management app has a feature that will let you postpone, delay, or snooze a task. You can tell them to push a todo item out by a day or a week, etc. But I like to think Three Things is smarter than that. Because the app knows that you can only do two or three things a day – and because it enforces that rule – the app knows when you do and do not have time available. So when you defer a task, it won’t accidentally reschedule it for a day that’s already overflowing with commitments. Instead, it smartly places it on a day that’s free.
But what about that “Defer All Tasks” menu item? Glad you asked.
Assuming you’ve scheduled your tasks in a mostly chronological order in which they need to be accomplished, then simply postponing one of them can delay others. I don’t want to get too far into the weeds of making one task depend strictly on another, but as an example: I often schedule out large app features I’m working on in bite sized pieces across a number of days. If you know how software development works, then you’ll know that you can’t normally just rearrange the order of those tasks.
So, with Three Things, when you defer all your tasks, the app will take all incomplete items scheduled today and in the future, and push them all ahead by one day.
But!
Some tasks really are due on a specific day. Again, I’m not trying to make this app a full-blow task management solution. I already have OmniFocus for that. But, each task can optionally be marked as deferrable or not.
If a task can’t be deferred, i.e., if it truly is due on a specific date, then when you defer everything else, all of you other items will flow around your scheduled tasks as appropriate. Your fixed-date commitments will stay put and the app will assume everything else is flexible and rescheduled them appropriately.
The way it works for me is before I shut down for the day (or sometimes before I get started the next morning), if there’s anything that didn’t get taken care of, I can defer all and Three Things fixes my schedule for me.
I know what you’re about to ask: Why not just use a calendar you weirdo?
Because that’s for things that have a scheduled time or hard due date. Because calendars are sacred ground that shan’t be fucked with or else they become meaningless. I’ve attempted to put my higher-level tasks onto a separate calendar alongside my real appointments, but it’s always too fiddly. Calendar apps are great at being calendars. But they’re almost universally lousy when it comes to todo lists. And in my case it’s even worse because the things I’m throwing at them don’t really belong on a specific date and don’t fall into the Reminders.app bucket either.
And dedicated task management apps are built for the individual items and low-level details of what needs to be done and in what order, etc.
Three Things isn’t either of those. It’s also not a project management app or a bug tracker. It’s not a Kanban board or a backlog.
By and large, everything I put into it is flexible and malleable. Its contents can mostly be shifted around, delayed, and rescheduled without consequence. I primarily use it to see how booked I am and to break down larger chunks of work into manageable pieces that could still themselves contain smaller actions.
Basically, it fits my brain. Maybe it’ll fit yours, too.
Current status of Three Things
I’m making Three Things available today for anyone to download and use. For now, the app is completely free. And that’s because while the app works, it still lacks polish, may or may not contain horrible-awful bugs, and is still missing a few small features I want to add before calling it one-point-oh.
Specifically, the app is missing the ability to:
Reorder tasks within a day. The plumbing and UI work is done – as you’ll see when you drag tasks from one day to another – but when you drop a task onto another day, it just positions it after any existing items on that day.
Assigning colors to tasks. Currently, all tasks are the same shade of blue.
An iOS version. I 100% plan on making an iOS companion app – especially because I want that for myself. No ETA on that yet.
Other random UI niceties and polish.
Data export. I have no intention of locking away your data in a proprietary format. The app will absolutely support importing/exporting everything as JSON and/or possibly a standard calendar feed.
Things that do work:
Mostly everything involving the day to day use of the app. You should be able to schedule new tasks, drag them to other days, mark them complete, and defer them. If any of that feels broken or I missed an edge case, I’d love to know.
iCloud sync! Yep, everything will stay in sync across all of your Macs.
Also, assuming at least one other person besides myself expresses interest in this app, I do plan on charging for it eventually. I’m not yet sure if it will be paid up-front with a free trial or some type of basic version with an in-app purchase to unlock extra features. I’d appreciate feedback on this.
Have at it. I’d absolutely love to hear any and all feedback you have. Bugs. Feature requests. Even if you just want to tell me this is the dumbest app idea ever. Please, feel free to reach out here or @tylerhall.
Today I lost about four hours debugging what I thought was a bizarre bug due to my own ignorance. Now, I don’t want to be too hard on myself – no one can be an expert in every nook and cranny of a tech stack as large as AppKit. But, still, this one really knocked me on my butt when I realized my mistake.
In today’s exciting episode of Tyler is a Professional Software Developer…
The bug I was running into happened when I dragged an NSTextField out of an NSStackView and dropped it elsewhere in the window. In the gif below you’ll see that after the drop completes, the NSTextField lingers behind – continuing to duplicate each time I drag and drop it.
Note: Only the originalNSTextField is draggable. The copies left behind don’t accept mouse events.
So, I start debugging this. My first thought is there’s some sort of race condition happening because when I drop the NSTextField, the change persists to my Core Data stack – which does the usual NSManagedObjectContext merge dance and then posts a notification letting the other views in the window know there’s new data and they should refresh. (I don’t know if that’s the proper way to do it, but it’s how I approached it in this situation.)
That notification ? refresh isn’t necessarily anything crazy or complex, but once the change finishes persisting to Core Data, my CloudKit code picks up the new data and pushes it up to the customer’s iCloud account. I don’t just do a push to CloudKit, though. The data model for this app is very, very tiny. So, I’m saving myself some added complexity and just doing an actual two-way sync each time. And, of course, when the sync completes – ? – my views are told to reload any additional changes from the sync session.
I’ve messed up code like this plenty of times before and I’m hoping my first instinct is correct and I’m somehow maybe adding an extra copy of the NSTextField twice to the NSStackView?
Here’s the pertinent code. It removes any existing tasks from the NStackView and then loops through the new data adding a view for each item back into the stack view.
monthDayView.clearTasks()
for t in tasks {
let taskView = t.taskView()
monthDayView.stackView.addArrangedSubview(taskView)
}
Heres’ the implementation for clearTasks() above:
func clearTasks() {
for view in stackView.arrangedSubviews {
stackView.removeArrangedSubview(view)
}
}
(For the seasoned NSStackView readers out there who can already see the bug in my code, please hold your laughter while I explain the next frustrating hour of my evening in excruciating detail…)
Seems safe enough, right? But still, my eyes don’t lie. There’s clearly a duplicate NSTextField hanging around. Let’s dig deeper.
I start with the app in this state:
I add this debugging code to confirm if the stack views really do or do not have the number of arranged views I’m expecting:
In the screenshot above, March 18 is the “real” item, and the other three are the weird zombie copies. For each of those views, the above debugging code gives me these results:
March, 18: 1 viewsOK!
March, 10: 0 viewswtf?
March, 16: 0 views ?
March, 24: 0 views ?
Um? That seems…wrong? Those extra views are clearly still there.
Firing up Xcode’s wonderful view debugger, however, completely blew my mind and shattered any remaining self-confidence I had as an app developer…
There’s not just one extra NSTextField hanging about. There. Are. Thirty. Of them.
Clearly at this point I am missing something incredibly obvious and foundational about the situation and frameworks in order for my (I think) relatively simple code to be breaking this badly. Let’s start from first principles and re-read the documentation.
Relatively speaking, NSStackView is a newish part of AppKit. It’s only been around since Mac OS X (not macOS) 10.9 Mavericks. Regardless, in the seven years since then, I haven’t ever really used it that often. I know it’s there and a nice tool to have available, but I’m just not super familiar with it. And as you’ll soon see, even less so than I thought.
I’m reading through Apple’s documentation in Xcode and I finally stumble upon removeArrangedSubview(_:)…
I think that’s strange for a seven year old API, but ok and keep browsing.
Nearly an hour later I’m really questioning everything I thought I knew about ones and zeroes until a google search leads me to this page. And, sure enough, my bug is spelled out right there:
However, using removeArrangedSubview()doesn’t remove the view altogether it keeps the view in memory, which is helpful if you plan to re-add it later on because you can avoid recreating it. Here, though, we actually want to remove the web view and destroy it entirely, and that can be done with a call to removeFromSuperview() instead.
Holleeee crap. I never knew stack views worked that way. (Thanks, Paul!) I mean, wow. That is a very basic misunderstanding on my part. So, I add one additional line of code:
func clearTasks() {
for view in stackView.arrangedSubviews {
stackView.removeArrangedSubview(view)
view.removeFromSuperview()
}
}
and ? it works. Not only does it work, but it also fixes a number of other peripheral bugs that I had logged but not investigated yet.
Anyway, I hope this excessively long post has enough keywords stuffed into it so that anyone else facing the same problem can find it.
But, last point. Why didn’t Apple’s documentation mention this very important detail? More so, why isn’t that method documented at all?
Ha, well. Turns out, they did document it. My empty screenshot above is from Xcode’s documentation browser. However, if you go to the same documentation on the developer website you’ll see…
So, I made a new app. Sort of. It’s called DefaultApp, and here it is…
Very minimalist, right? Here’s a screenshot of the Preferences and About windows…
And that’s the whole app. It’s not something you can actually use or do anything with. Instead, it’s an app you can build something new with.
DefaultApp is an open source starting point – a template. I maintained it in Objective-C for over a decade before finally porting it to Swift in 2018. Anytime I start a new app – big or small, whether or not it’s something I plan on releasing publicly or if it’s just a small prototype or utility app I’m building for myself – I start with this project.
I very much build software in fits and spurts while running off the adrenaline of a new idea. And if I just want to quickly try out an idea, the time from Xcode ? New Project to getting all my usual settings and dependencies in place to where I can actually start working on whatever I have in mind is thirty minutes full of friction, busy work, and me cursing myself every time I screw up some dumb little configuration detail. And when my brain is running at a thousand miles per hour thinking about the possibilities of what I want to build, that half hour of just getting to the point where I can get started is excruciating and a motivation killer.
But with DefaultApp I can go from initial idea to writing actual code in thirty seconds.
Every major web framework has a projectlikethis already. This is nothing new. DefaultApp is basically a glorified “Hello World” project but with my own highly-opinionated choices and foundational level code snippets included to help get things moving quickly.
You can read the details of the project in the README, but here’s the tl;dr of what’s included:
It builds a native macOS app targeting 10.14 Mojave and 10.15 Catalina.
A hardened-runtime target ready for Notarization and designed to be distributed directly to your customers.
A second, duplicate target that is Sandboxed and ready for distribution via the Mac App Store.
Conditional build flags that let you differentiate between debug and production builds as well as Mac App Store and direct to consumer builds.
It also builds an iOS companion app target for iOS 13 with shared code between the two platforms.
Default NSWindowControllers for a primary app window and Preferences window are wired up and ready to go. They’re also built using xibs because storyboards on macOS are dumb.
The app is AppleScript enabled by default and includes a sample .sdef scripting dictionary because you can pry AppleScript support out of my cold, dead hands.
Sane Xcode defaults for settings such as enabling insecure HTTP requests in web views but not in the rest of the app and also making the project compatible with agvtool. Little things such as those that are helpful but nearly impossible to google unless you know what you don’t know.
Pre-configured to check for app updates with Sparkle. (And in the Mac App Store target, Sparkle is completely removed to appease the App Review gods.)
A fair amount of other miscellaneous code and helper extensions that always come up and no one wants to write from scratch each time.
Pre-written Podfile and Cartfiles that include the usual open source libraries I include in all of my projects. (I would have migrated to the Swift Package Manager instead, but not everything is available through it yet.)
As I said above, the default settings and choices made in this project are my own highly opinionated way of doing things. And I’m well aware I approach things differently than other developers. As a solo dev running my own company, my highest priorities are being pragmatic and efficient. So I make use of tools that allow me to move the fastest regardless of whether or not they’re in vogue. I lean on open source projects that are reliable and cost effective for a small (no, tiny) software business.
My most popular GitHub repo is the Simple PHP Framework. It contains code dating back to 2005 that was organically gathered and grouped together into a foundation that I still use to this day to build all of my websites with. Would I use it to build a giant online storefront or a complex backend API? Maybe? It’s certainly been used in those situations before. But it’s really aimed at single developers or small teams who want to get shit done fast and with minimal fuss.
I view DefaultApp as my equivalent project for macOS development. While it certainly works for me and serves as the basis for all of my apps, I don’t know yet if it will work well for others the way my PHP framework has over the years. I guess what I’m saying is don’t use this as the basis for a billion dollar corporation’s enterprise app. Or with a team of “100 engineers” “solving hard problems”.
But if you’re a one-person development shop or a team of just two or three engineers building a typical macOS shoebox or document based app? Please take a look. Or, if you’re just getting your feet wet in Mac development and want to see how someone who’s had moderate success on the platform structures a new project, you might find it helpful – particularly the three classes related to implementing an NSOutlineView.
(Sorry, that line just sounds so arrogant when I read it, but I’m not sure how else to put it. I’ve been writing Mac apps for seventeen years now, and despite my many (probably) unorthodox development practices, I ship consistently and earn a decent income. My 21 year-old self would never have believed I’d even reach the point I’m at now. Before I finally found the Hillegass book on a bottom shelf in Barnes & Noble in 2004, 2003 Tyler would have killed for an example project like this. Native Mac apps feel like a dying breed that are succumbing to janky web views and (mostly) awful Catalyst ports. If DefaultApp can help just one developer new to the platform get started, then I’ll be ecstatic.)
Anyway, this is the first release of DefaultApp. I’ve got more old projects I’ve yet to comb through for other useful snippets to include, but this is nonetheless a good starting point for when you’re building a simple to moderately complex Mac app or just want to create a quick prototype.
Nice article on photos backup! Have you considered amazon S3 glacier instead of B2? It should be cheaper and work with Arq , can I ask why you prefer B2?
I started to reply directly, but then like everything I write, it kept growing. And then I thought my answer might be interesting to others as well. So, here you go…
Hey. Glad you enjoyed the post. I’ve looked into Glacier previously, but stick with B2 for a few reasons. Just specifically talking about my photos/videos (not my actual computer backups which I do use Arq for)…
B2 currently costs me $5/month. Glacier Deep Archive would be $1.80/month just for the storage.
However, assuming I’m doing Amazon’s complicated pricing math correctly, in the event of a full recovery, getting all of my data out of B2 would be $10. But a restore from Glacier would be $90.
Do I expect to need to get all that data out very often? If ever? Hopefully not. And with my local backup and the fact the Google truly is super reliable despite me being paranoid, I haven’t ever had to restore a single photo or video from B2 yet. It’s purely my disaster recovery fallback.
So, in theory. It would cost an extra $80 to restore out of Glacier, but be $3.20 cheaper per month for storage. $80 / $3.20 means I could do a full restore once every two years and break even compared to B2. And if I never did do a restore, I’d save $76 over the course of those two years.
So now that I’m doing the math again, maybe Glacier is something to look into long-term as my storage needs keep rising. But, thankfully, I’m very fortunate that an extra $3/month doesn’t bother me enough to invest the time into migrating and figuring out an alternative to B2’s easy to use command line sync tool. Does s3cmd offer similar functionality? Maybe? I’ve never looked to see if it does syncing. Update: Yep, it does. Nice.
Anyway, given all of the above and also your initial mention about how Arq would work with S3/Glacier, I do want to point out that I’m not using Arq for my photos and videos.
I do use Arq to backup my computers because I love having a way to restore specific versions of my files. And Arq’s restore UI works terrifically. It’s saved my butt a number of times.
Also, because of bandwidth constraints, I can’t actually use Arq for my giant, monthly photo and video backup job. Arq is a Mac app – so I’d have to run it at home behind my Comcast connection, which has terrible upload speeds. Sure, it’d be doable. But it’s way, way faster to go datacenter to datacenter, which means I need to use a different tool.
Speaking of which, as I said above, I’ve never needed to restore my photos from B2 yet. But I do frequently grab old files (sometimes 100s of GB) with Arq. That sort of access with Glacier isn’t cost effective – B2 is way cheaper. Also, B2 gives me instant access to my files whereas Glacier might require waiting 12 hours.
Anyway, that’s my calculus. I don’t ever really foresee moving away from Arq + B2 unless Arq is discontinued or an even cheaper B2 competitor appears. But as my family archives keep growing and eventually cross into multiple TB, I may need to reconsider Glacier.
Note: If I totally screwed up the Glacier pricing, I’d love to hear about it. I estimated the costs of archiving and restoring a flat 1TB.
Two of the topics I’ve written about the most on this blog are backing up your data and also photography – not professional, artsy photography, but more in the sense of your family’s photo and home video library. I’m a huge nerd for these topics. Part of the reason for that is my own obsessive personality traits, but also because of my affinity for nostalgia and history. My life, to a certain degree, is documented through the literal data I’ve created over the years. And the lives of the people I love are likewise documented through the digital archives I keep. So when those two topics intersect, holy cow do I ever proudly fly my geek flag.
There’s no need to rehash how much things have changed since then. I could go on and on about how the backup options available to consumers have evolved as well as how we’re simply generating exponentially more data. In fact, I do go into all of that here and here. Instead, I want to specifically talk about how I’m managing my family’s photo and video archives from two perspectives:
Purely from a data safety perspective. That means ensuring nothing ever gets lost.
And also from a usability point of view. Unlike other types of long-term data storage, the whole point of keeping your photos and home videos safe is to be able enjoy them. If they’re only stored on Blu-rays or magnetic tape drives kept in a bank vault, that kinda defeats the purpose.
The last time I wrote about this topic I thought I had everything figured out. And for a while I did. But it (surprise!) turned out that the Rube Goldberg machine I had created using rclone, rsync, and the Google Drive API as a workaround way to access my Google Photos, was a little too fragile. My aim back then was to make as much of the process as automatic as possible. In hindsight, I think that was too lofty a goal. Over the last nine months I’ve settled on a more manual, monthly backup strategy that I’ve found to be a good compromise. It Works For Me?
99% of my family’s photos and videos come from mine or my wife’s phone. We’ve had two DSLRs over the years. And even bought a nice camera specifically for when my son was born at the recommendation of Shawn Blanc. But they’ve all fallen by the wayside as camera phones have gotten so damn good. (Also, something something about the best camera is the one you have with you.) So, nearly every photo we take comes from one of our iPhones.
The other remaining one percent? That comes from photos other people take of our kids and post to a shared iCloud photo stream. I did have a decent system in place for backing those up, but then, well, shit. So I’m still not sure what to do about them anymore 🤷♀️.
Anyway, my family’s photo and video collection is currently weighing in right at one terabyte. For a long time I managed to keep it all stored and organized in Dropbox. I even wrote an app specifically to help with that. (As well as a book I never finished writing.) Eventually, though, that became untenable and I bit the bullet and switched to Google Photos. And Google pretty much solves the usability aspect of this puzzle for me. You can read that linked post for the reasons why I think it’s an incredible product.
Both my phone and my wife’s phone backup automatically to Google. A year or so after we made the switch, Google debuted partner accounts that let you automatically share your library with one other person. That’s awesome – and something I think Apple is sorely missing. But given that my wife and I had already settled on a solution that worked for us and also that having a second Google account involved would complicate the backup process I outline below, we still use the old trick of having the Google Photos iOS app signed into my account on both our phones.
So, that’s what needs to be backed up in a safe and sensible manner: 1TB of data stored in Google’s cloud. How do I go about it? I’ll tell you. But first…
Let’s talk about Amazon Photos and the cost of the cloud
Amazon debuted their Google Photos competitor in 2014 (I think). I gave it a brief try around 2015 or 2016, but I was very much underwhelmed. I remember it being decidedly not good and wrote it off. But late last year, for reasons I don’t really remember, I thought I’d take another look. And you know what?
It’s really good. Like, really, really good. Light years ahead of what I remember first trying.
For the last two years I’ve been looking towards the future and the ever increasing size of my photo library and hoping for a way out of Google. I certainly worry about the privacy implications of willingly paying Google to slurp up even more of my private data, but, meh. I don’t know of another alternative, and (for now) I’m willing to make the tradeoff given the benefits Google Photos offers. My biggest concern is the expensive brick wall I’m going to run into in the next year or two when I estimate I’ll cross into the next storage tier.
As I said, I’m currently using 1TB of data. My current Google One storage plan is $9.99/month for 2TB. That’s the same pricing as what Apple offers with iCloud. But what happens when I reach 2TB and 1 byte? The next option is 10TB of storage for $99.99/month.
Uh, that’s quite a jump. And I’m not even saying the price is unreasonable. If I had 10TB of data to store, I’d be fine paying that much. (Even B2 would cost $50/month.) And, to be fair to Google, at least they offer the option. Apple doesn’t even offer a higher iCloud storage tier than 2TB. When my family maxes that out? I guess our phones will just stop working?
But even as quickly as my data needs are growing, it’ll be a long time before I can justify $100/month. And so that’s why I decided to give Amazon Photos a full-on, complete, all-in try. Take a look at their pricing:
(Oh, and I should point out a bonus about using Amazon. If you’re a Prime member, you can store an unlimited number of full-res, original quality photos and they don’t count against your quota. So, the extra storage space you’re paying for only needs to cover your videos. That can be a potentially huge cost saver.)
I’m assuming Amazon is more concerned with purely making a profit on their storage costs because they have plenty of intermediate tiers that reasonably increase in cost as your storage needs grow. In my case, going one byte over 2TB with Google would be $1,200 a year for 10TB. Amazon would only be $180 for 3TB. And so with $1,020 on the line, I wanted to give Amazon Photos a fair shake and see if they were a viable alternative.
Spoiler: they’re not. At least not yet. But it was so damn close.
Let’s start with the good parts.
Amazon’s app, while maybe not as pretty as Google Photos, is far more functional and snappier to use. What I mean is, when I look at Amazon Photos from an iOS developer’s point of view, it appears to be built with, you know, UIKit.
Google Photos? I get the horrible feeling they’re attempting some shared codebase, cross-platform, UI framework shenanigans that only the engineers at a multi-billion dollar corporation intent on solving “hard problems” think they can pull off. Like pretty much all of their iOS apps, it feels completely foreign on the platform. But UX issues aside, it just doesn’t perform as smoothly. When I scroll through a long stream of photos, I can just feel all the layers of indirection and architecture they’ve built working furiously just to be able to display an image loaded over the network.
Amazon on the other hand – their shit is fast. It feels fluid and responsive in a way that only truly native apps do. Even on a mediocre LTE connection, images scroll on screen just as fast as I can scroll to them. The same is true about both of their web apps. It feels like Amazon is using a bunch of <img> tags inside a <table> (not really, of course). Meanwhile, Google is playing fast and loose with the DOM to reimplement scrolling from scratch for reasons only god knows why. I hardly ever see any blank / placeholder images with Amazon while I wait for the network to catch up. Google on the other hand…
After a bit of looking, Marissa explained that they found an uncontrolled variable. The page with 10 results took .4 seconds to generate. The page with 30 results took .9 seconds. Half a second delay caused a 20% drop in traffic. Half a second delay killed user satisfaction.
This conclusion may be surprising — people notice a half second delay? — but we had a similar experience at Amazon.com. In A/B tests, we tried delaying the page in increments of 100 milliseconds and found that even very small delays would result in substantial and costly drops in revenue.
the Google Photos app just feels slow in comparison.
Next up. Amazon’s sidebar filter. Oh. My. Goodness. It ticks my nerd checkboxes so hard.
With Google Photos you just have a search box. That’s it. And I get it. Google is built around search. The idea is to just type what you’re looking for and Google will give you that. And it works.
Until it doesn’t. Because it’s a black box, you have no idea if Google is interpreting your query correctly. There’s no documentation. No real search syntax to reference. You just have to sort of blindly experiment and hope Google understands what you’re asking for.
And, sure, Amazon has a search box, too. But being able to literally see the number of photos across all of the data points and categories Amazon has grouped your library into, and then being able to mix and match, sort and filter them live – until you’ve narrowed down to exactly what you need – is so incredibly refreshing and a delight to use.
The last super awesome feature I’ll highlight is a trend in consumer software that drives me absolutely up the wall. And that’s lack feedback when something goes wrong.
In my day to day life, Apple is by far the biggest offender. Almost daily, something iCloud or otherwise network related will fuck up on Mac or iOS, and the UI will just sit there with a dumb grin on its face like nothing is wrong. There will be no error message or any sort of actionable feedback about what went wrong. They’ve stripped the UI of so many progress indicators that often times you have no idea if anything is actually happening or if your task has just silently failed. Or, worse, there will be a progress indicator – but in the case of Photos.app on macOS – when you export a video it will remain at 0% for minutes upon minutes with no progress shown. Until finally, and suddenly, the job will finish despite never showing more than 0% complete. (NSProgress exists. Use it!)
/rant over
The Google Photos app is guilty of this as well. Many, many times the app will report that an image or video cannot be uploaded. Occasionally there might be a vague message saying the item was “unsupported” – despite the fact that it’s just a regular image taken with my iPhone. Same as the 80,000 the app has previously uploaded for me. And that’s it. No details. No way to try again or learn more about what went wrong or what might be done about it. Just a mostly silent failure.
Last Fall, my wife’s phone stopped backing up completely. The Google Photos app would not attempt to backup any new photos she took beyond a certain date. Logout / login. Delete the app and reinstall. Nothing worked. And, of course, there were zero error messages or even any indication anything was wrong or failing. Finally, we wiped her phone clean, let iCloud sync her photos back to the device, and tried again. Only then did Google start backing up once more. The cause? The solution? I have no real idea.
Now, compare that to Amazon’s app.
Bless those engineers. Look at all those glorious progress bars and detailed status labels. And when something does go wrong?
An actual error message with what went wrong! The product team that designed that screen would obviously never make it at a real Silicon Valley tech company.
Dealbreakers
With all the great things I said above about Amazon’s offering, why didn’t I stick with them? For a thousand paper cut reasons and one really big reason. First, here’s an email I sent to their feedback address.
Hi, Amazon folks.
I’m looking to move entirely away from Google Photos to Amazon. I’m really, really liking your product so far – especially being able to use the options on the left sidebar to explicitly filter combinations of people/places/dates. That’s a huge improvement over Google’s “only a search field” approach where I have to search and just hope Google figures out what I want.
I’ve successfully imported my 80,000 photos/videos from Google and recreated my 400+ albums. But there are a few key features that are preventing me from fully switching…
All of my albums follow the naming convention of “YYYY-MM Some Title”. For example “2019-06 Aaron’s 5th Birthday Party” or “2008-07 Beach Vacation”. This lets me sort by name and have them ordered chronologically. Unfortunately, in Amazon Photos I can’t search by album name. And with 400+ albums, that’s a huge problem.
Using the search field at the top of the page, I can enter a query and pause, and the search field will autocomplete and show a list of matching album names, but it’s extremely limited and not quite accurate enough. Here’s what I mean…
Say I have the following albums in my account:
* 2019-06 Aaron’s 5th Birthday Party * 2019-06 Summer Camp * 2019-01 New Year’s Party * 2008-07 Beach Vacation * etc
If I type “2019-06” into the search field and wait, it will correctly list the two matching albums. However, it will only display at most five results. If I have more matching album names than that, I can’t see them. If I actually perform the search (“2019-06”), the full search results page doesn’t list any matching albums – only individual photos ordered by date – no albums.
Also, going back to the search field, if I were to type “Party”, it doesn’t list any results despite there being (at least) two albums with the word “Party” in their names. It appears that the autocomplete results are only matching by the beginning of the album name – not by words within the full album name. And, again, even if the autocomplete results were more helpful, the full results page still isn’t returning results for albums.
Thanks for reading all the above. Your AI/ML based search results are a nice bonus feature for finding what I’m looking for, but for myself and the way I organize my family’s photo library, I really need to be able to do just a basic keyword search by album name.
Oh, and if it helps provide some weight behind my feedback: I’m a Prime member and also recently upgraded to an additional 1TB paid storage plan just for Amazon Photos. I’m sure my storage needs will continue to increase over time.
Happy to provide more detailed feedback if you have questions.
Cheers. Tyler Hall
Even given that feedback, I was very much still on the fence. Until I hit a showstopper.
I have quite a few large videos in my library. They’re nothing insane. I’m not trying to upload blu-ray rips. But iOS now shoots video at 4k / 60fps. And I’ll occasionally take a 10+ minute home video. That’s easily multiple gigabytes in size. The Amazon iOS app handles files that size with no problems, but their server backend chokes.
I noticed this behavior with two videos – each 10 to 15 minutes long. Multiple days after uploading to their cloud, the website will show a thumbnail preview of the video, but it won’t play. Instead, it gives an error message saying the video cannot be played in a browser and I should use a mobile app instead. Ok, fine. But even on a stable wifi connection, those two videos would simply never play on any device. And I don’t mean they buffered or stuttered. Playback would just never start. Even if I dragged the scrubber to another point in the video, nothing. I tried again days later hoping that videos that big just needed extra time to process. But, the same result. I will say that I did try and download the raw video file and that worked fine. So my data was safe and backed up. It simply wasn’t viewable.
So, for me, that was a bug, breach of trust, a bridge too far, whatever you want to call it that made me realize I couldn’t fully switch to their product. At least not yet. But I’ll check back maybe in another year.
With Amazon out of the running, I still don’t know what I’m going to do when I hit Apple and Google’s next storage limit. But I estimate I have a least another 18 months before that becomes a problem.
Back to backing up my data – the whole point of this post. Here’s my solution.
My (Current) Google Photos Backup Strategy
I don’t trust Apple’s cloud. I don’t trust Google’s cloud. I don’t really trust anyone’s cloud for a number of reasons.
When Apple does their best work, it’s often the best in the industry. But that’s becoming increasingly rare as the services we depend on become more and more complex, and, quite frankly, I’ve experienced enoughbugs (worse – intermittentbugs) and poor product decisions that I’ve lost faith. They have my business, certainly, but they don’t have my trust.
Even though I’m paying Google for extra storage space, I’m not their customer. I’m a product to be sold to their advertisers. And that puts me in a position where I have no leverage if something goes wrong. At any point one of their automated systems could flag me for a TOS violation and my account would simply be gone along with my data. It happened to my original Yahoo! account. It happened to my Twitter Developer account. It’s one of the main reasons why I quit Gmail years ago. And so I refuse to put all of my eggs in the basket of a company I can’t hold accountable.
I don’t actually fear any cloud losing my data due to a hardware failure. My worries all revolve around an application error or process failure. I’m in love with the benefits our new services culture offers, but I don’t trust the system for a moment. If I don’t have a backup of my data under my control, then it may as well not exist.
I also don’t trust that my house won’t burn down. And my photos and videos are too precious to me to take a chance with. So, I want them in three places at all times:
In Google Photos where they’re useable.
Locally on an external backup drive at my house where they’re accessible.
Google Photos should be the source of truth. It’s where my photos go first and how I organize them. B2 and my local copy should be a mirror of that and of each other.
If performing these backups becomes too time consuming or tedious, it won’t get done. And if you don’t have regular backups, why have any at all? And because each backup set might involve tens of gigabytes of new data, the whole process needs to be manageable from a 200 Mb/s Comcast Business connection. That’s the fastest internet I reasonably have access to.
So, every month on the 5th, I backup the previous month’s worth of photos and videos. Why the 5th day of the month? To stay organized, I literally only operate on and worry about days 1 – 30 of the previous month. By waiting to the 5th I can be reasonably sure of and notice if any stragglers from mine or my wife’s phones didn’t get uploaded.
The first step is to use Google Takeout to request a backup of my data. Doing a full Google Photos dump each month would be insane. Instead, Google helpfully allows you to choose specific albums and/or dates to archive.
Request the backup, and then a few hours or maybe a day or two later, Google will email you when your data is ready. For reference, here’s the February 2020 backup I requested a few days ago:
You’re seeing that correctly. My February archive was too big for a single 50GB .tgz file. So, Google helpfully split it into two. Ooof.
As I said above, I’m on a Comcast Business connection, so my download speeds are perfectly adequate. But it’s not fiber. And once I download 100GB and store it locally, I still then have to re-upload to B2. And my upload speeds are abysmal. So that’s out. Instead, I work around the bandwidth constraints like this.
I spin up a Linode (or DigitalOcean depending on my mood) VPS with just enough storage. For last month’s 100GB export, I went with an $80/month Linode that includes 320GB of storage. (Think: 100GB across two .tgz files and then double that once they’re extracted.) Don’t lose your mind yet. This whole process only takes an hour or two. So that $80/month price actually works out to less than $0.30 for the short amount of time I need it.
With plenty of storage and a fast cloud connection (I make sure to spin up the VPS in a California location since that’s where B2’s datacenter is), I download the Google Takeout archives remotely, extract, and sync to B2.
But wait! If you go this route you’ll find that the download URLs Google provides are protected behind your Google Account (as they should be). And since I’m doing all of this over an SSH connection to my VPS, I can’t exactly just give them to curl to do its thing. I’ll be unauthenticated and get rejected.
I toyed with various idea for how to login or spoof cookies or something, but I finally landed on a much simpler and more pragmatic solution. Using Charles Proxy as an SSL man-in-the-middle, I use Safari on my Mac to begin the download. Then, I kill it. Go to Charles and find that failed connection, right-click, and Copy cURL Request.
That literally puts the correct curl command on my clipboard including all of Google’s insane HTTP headers and authentication cookies. I can then just paste that into my shell and watch a 50GB file download in a matter of minutes.
Next, I extract the file, and use B2’s official command line tool to sync the new photos and videos into my bucket. Going datacenter to datacenter, it never takes longer than twenty minutes. Once the transfer is complete, I run the sync command a couple more times just to verify and let it report back that all files were copied successfully. Only then do I delete my data and destroy the VPS. And like I said earlier, the machine is only alive for at most an hour or two. So the costs never exceed $0.50 – even including bandwidth charges.
Your milage will vary, of course, but here’s the basic commands I use on the VPS (recent Ubuntu flavor) to install the B2 command line tool, download from Google, and sync to Backblaze.
The final step is to get the new data back down locally to my external drive. I also use B2’s command line tool for that. I’m lucky that downloading a hundred gigs of data only takes an hour or so. Even still, and even if it took multiple days, my iMac is always online so I just start the job and let it run however long it takes.
Ok, the final, final step is only sorta related to all this. Because storage is insanely cheap now, I also keep complete backups of my iCloud photo library as well as my wife’s in B2. Doing this is easier than backing up Google Photos. We each have accounts on my iMac with Photos.app set to download the original files of all our media. Then, I just setup Arq to backup to B2 every day and forget about it. It’s purely done as an ultimate last-ditch recovery solution in the event of a real disaster or if I manage to corrupt my other backups.
Next Steps
So that’s basically it. Nearly 4,000 words just to explain the convoluted process and reasons for how I backup my photo library. If the past has taught me anything, it’s that this strategy is likely to change in the future as well. As the amount of data we generate increases, bandwidth speeds up, and cloud and local storage prices fall, I feel like we’re at or nearing an inflection point where I can’t even imagine what my needs will be in the near future – much less years from now when I hand over the family archives to my kids for safe keeping as my aging father recently did to me with his own decades’ worth of genealogy research.
In the near term, my open questions are what will happen when my family hits the 2TB iCloud max? Apple doesn’t even offer a higher tier to pay for. I know that eventually they’ll recalibrate and increase their storage as the average Mac and iOS customer consumes more data. But if (when) I hit that limit before they do? I don’t know what to do other than just erase my iCloud photo library and depend entirely on Google Photos.
And speaking of, we’re going to hit our current 2TB plan’s ceiling within two years. And it’s a helluva jump from paying $10 a month to $100. I guess I’ll just have to move to Amazon at that point regardless of any remaining showstoppers in their product. And when I do, I’ll be sure to write about and publish the command line tools I wrote in Swift to migrate my library from Google to Amazon.
A Final Anecdote
In the first half of this post, and indeed in many, many of my posts on this blog and on Twitter during the last year or so, I’ve bitched about Apple and how I (and many others) perceive their recent software quality. Bugs, lazy decision making, too many balls in the air, etc. Certainly I could have been kinder in many of my assessments, but I stand behind everything I’ve written.
That said, a quick anecdote that I haven’t ever mentioned publicly.
After my Catalina rant gained attention last October, an Apple executive personally reached out to me via email. While it wasn’t exactly like one of those fabled responses out of the blue from Steve Jobs, it was along those lines in spirit. Over the course of a weekend we had a good discussion about the state of the Mac, how customers, developers, and shareholders like myself perceive Apple’s attention to the platform, as well as how this executive viewed the company’s commitment to the Mac – both software and hardware.
We certainly didn’t see eye to eye on every topic, and I’m not entirely sure how much of what they said were their honest feelings versus what their obvious PR training allowed them to say. But, it was a productive conversation. And whether or not they thought I was full of shit (I usually am) they did genuinely listen and demonstrate that they cared. I know this because
As our exchange was winding down, they setup a phone call between myself and an Apple engineering manager to do a deep dive into some of the technical points I brought up in my Catalina post and over email. That manager turned out to be incredibly smart, thoughtful, and willing to consider and debate every suggestion I had. Every interaction I’ve had with Apple engineers in the WWDC labs has been excellent. This was no different.
During our emails, I mentioned my pet peeve from earlier in this post about the lack of visual feedback, progress indicators, and silent failures that have crept into macOS. I offered to make a quick screen recording and also put together some examples to illustrate my points. They said that would be great, and when I sent them a link to a nearly 1GB zip file of videos and annotated PDFs on a Saturday morning, they replied a few hours later that “I’ve forwarded it to the team and they’re already looking into”. Okay. That’s nice to say but obviously lip service. At least I thought it was until I thought to check my server logs on Monday and saw that the file had been downloaded by nearly twenty internal Apple IPs Saturday afternoon and Sunday morning.
My point with all of that is that I’m going to keep bitching on Twitter and on this blog whenever I see shortcomings in Apple’s software and when I don’t agree with the direction they’re moving. But I am going to try and be kinder to the people behind the products. Because I know they are listening (to all of us, not just dumb me). And because this person took the time to demonstrate they obviously care.
I’m a firm believer in the whole mind like water spiel that David Allen preaches through GTD. I jumped on the Gettings Things Done bandwagon around 2004 I think – the first of my two senior years in college. And here we are in 2020, which means I’ve been practicing this methodology (with varying levels of success) for over fifteen years. And now, looking back, I can see that it was probably 2010 – six years in! – before I became truly comfortable with letting go; before that whole mind like water state of flow finally became second nature.
For me, and I guess most people doing the GTD thing, getting to that point meant fully trusting your system. And that’s exactly what I mean when I say “letting go” above. You have to train yourself to be diligent enough that putting everything into your system becomes habit. And you have to trust your system (paper, digital, whatever) enough so that all those open loops in your head fall away and you can just let go and go about your life confidently.
Years ago, I worked on a piece of medical software that was designed to ensure surgeons operated on the correct side and limb of the patient’s body. It’s the 21st century; you’d think the medical industry would have fixed that problem by now, right? But even after verbally confirming with the patient before surgery, and then even after marking the incision site with a Sharpie, doctors still occasionally operate on the wrong part of the body. The software I helped build aimed to solve this problem by being a glorified, cloud-synced checklist that hospitals could buy for tens of thousands of dollars per license. (Enterprise software sales is ridiculous.) And I’ll be damned, but the research showed that medical facilities using our software reported a statistical decrease in operating room screwups.
That point of that story is to say that checklists – particularly ones that recur and involve multiple, detailed steps – can be an amazing tool to have at your disposal. And learning to use them was a huge part in my own journey towards letting go of all the crap in my head.
And so, for a long time now, I’ve been using checklists for all of the recurring, multi-step projects in my life. Here are some examples:
Releasing an update to one of my Mac apps is a twelve step process. Some of it can be automated – but not all. And if I forget or mess up any one of those steps, it could botch the whole release.
At the start of every month, I sort, organize, and backup all of the photos and videos my family took during the previous month. Because of the sheer quantity of data we generate every 30 days – and also the fact that I’m slightly crazy and don’t trust any single cloud provider with my memories – that backup process involves syncing tens of gigabytes of data and a bunch of shell commands. Once again, it’s not something I trust myself to get right every time on my own.
Every three months I have to renew and ship an updated SSL certificate inside one of my apps. If I forget, or if I mess up, my customers won’t be able to get their work done. This is also another fairly involved process that I can’t easily automate, so I have to do it by hand.
Originally, and for nearly a decade, all of those checklists lived inside OmniFocus as recurring projects. And by and large that worked really, really well. But in early 2019, when I found myself with a bunch of free time on my hands, I took a week to reevaluate all of the systems, inboxes, apps, and habits I use to get life done. One of the best changes that came out of that week was a new approach to handling those repeating projects. And it makes use of two of my very-most-favorite apps: TaskPaper and Keyboard Maestro.
They key insight I had was that while my checklists in OmniFocus were definitely helping make sure I do the things I’m supposed to do, they were limiting in two ways:
Tasks in OmniFocus aren’t very good at holding detailed information about the task – information you might need to actually do the task. There are a few standard approaches to solving this limitation. OmniFocus does have a “Notes” field associated with each task, but it’s basically just a small textview – not really anything you would want to type in or view a sizable amount of text with. Or, you could use the “Notes” field as a pointer to link to some other actual document in your reference system. Many apps now let you copy a unique URL that will link back to the source document. That’s super handy, but in practice I’ve always found it a bit clunky, clumsy, and fragile.
The other drawback to having everything in OmniFocus was that I was not capturing any of the metadata around those tasks as I completed them. When you mark a task complete in OmniFocus, the only thing that’s actually recorded is the completion date. If something unusual happens or goes wrong with one of my tasks, I don’t really have a way for my future self to reference or learn from the mistake. Or say everything went totally fine and normal, but I just need to store some piece of information particular to a task. Where does that go? Again, OmniFocus has that “Notes” field, but I just don’t find it very usable in practice – especially since the app isn’t really optimized for going back in time to reference past actions. (Nor should it be, really.)
To fix those two shortcomings, what I ended up doing was converting all of those recurring projects into TaskPaper documents. Each document contains all of the actions for the project, which of course can be nested and organized just like they were structured in OmniFocus. Then, back in OmniFocus, I deleted the project and replaced it with a single recurring task that reminds me when it’s time to start the project again.
When that time arrives, I make a duplicate of the template TaskPaper document just for that specific recurrence of the project and work my way through the checklist like normal. Having everything stored inside the TaskPaper document solves the two problems above.
It’s a plain text file that can be opened with TaskPaper or any other text editor. So, I’m free to add in as much supporting material for each task as I want. I can literally drop in paragraphs and paragraphs of prose between each task if I need to. Or, some of those projects might require technical details. I can just inline those in the document itself. The same goes for actual URLs linking to other supporting materials or websites.
If I need to take notes, remember anything about a particular task as it happens, or record the outcome or any results of the work, I store that in the document, too. That way, everything is self-contained and in the correct context if I ever need to reference what happened. And, again, since it’s all plain text – everything is easily searchable from Spotlight all the way down to grep.
After the project is complete, I file away the TaskPaper document for safe keeping.
So that’s the theory behind the system I’ve migrated to – and it works great. But what does it actually look like in practice? As an example, let’s look at my monthly project that backs up my family’s photos and videos. (My workflow is slightly insane, but I have “reasons”.) In OmniFocus, that project looked like this:
And that’s great. That gets the job done and makes sure I don’t miss a step. It also helps because some of these steps can take an hour or more of waiting around for data to transfer, so if I get distracted by something else while waiting, I know exactly where to pick back up from.
But, there’s also a lot of complexity behind each of those actions. The “configure server” step involves running a shell script. Where should that be stored? I find it’s a bit of a balancing act between keeping reference material contextualized alongside the task itself vs keeping it in some type of external storage (DEVONthink, Evernote, Apple Notes, Bear, etc). In this particular case, I like having it right there. And that’s not very easy with OmniFocus. (This isn’t me bitching about OF. I don’t think or know if it should even be a use case they support. There are better tools for that job, which is what I’m leading up to.)
Now, compare that to what the TaskPaper document for that project looks like:
Same thing – but now I can inline the information I need to complete each step. For this project, that happens to be all of the necessary shell commands.
So, ?, TaskPaper is great for this sort of thing. But as more and more of those documents are created each week and month, where do they all go? How are they managed, etc? Glad you asked.
They’re stored in a simple directory structure in a dedicated Dropbox folder, so they’re in sync and available on every device.
(I’ve removed a year’s worth of archives from that screenshot so you can see the full folder structure in a single image.)
It works like this:
Lists is a top-level folder in my ~/Dropbox. The checklists that are active / incomplete and that I’m currently working on live in this folder.
_Templates stores the templates / original copies of the TaskPaper documents that I duplicate and work from.
_Archives is where the files go once they’re completed so I have a single place to search / reference in the future. Also, many times, it’s where incomplete lists go once I give up and abandon one for whatever reason – as is often the case when I just don’t get around to completely finishing my weekly review every Sunday.
Each file has the same name as the template it was duplicated from but with the current date prepended so I can keep track of things and also sort by date in Finder.
I know all of this may sound like overkill to lots of people (especially to my family and coworkers as I watch their eyes glaze over when I get excited and start rambling on about this stuff), but it keeps me on track. More importantly, because I have this system in place – one that works for my weird, specific way of doing things – it truly allows me to let go and do my work knowing that things won’t fall through the cracks.
When I first read the GTD book and was introduced to mind like water and all that stuff, the idea was fascinating to me because it echoed the feeling of flow that most developers (and tons of other creatives and professions, of course) strive to get into when doing focused work. And not having a bunch of baggage in your head about all the things you need to do but can’t yet actually do is freeing and makes it easier for me to do my best work.
Ok, enough philosophizing. Here’s the last thing. It’s a quick Keyboard Maestro macro I wrote that makes this workflow instant.
At any time on my Mac, I can hit ⌘⇧\ (my keyboard shortcut to bring up KM’s macro picker), type the name of a list template, and press ↵. Keyboard Maestro will duplicate the template, put it in the correct folder, give it the appropriate date formatted filename, and open it in TaskPaper.
The macro is smart in that you don’t have to manually specify each list you want to work with. Instead, just add a new template into the _Templates folder, and Keyboard Maestro will read its directory contents each time you run the macro. That way, everything’s always current and available.
And here’s the macro in all its glory, which you can download.
The first digital music purchase I ever made was Eric Clapton’s Me and Mr. Johnson in April 2004 from iTunes. Since then, (I just looked this up) I’ve bought an additional 3,245 songs from Apple.
I couldn’t find a quick way to count how many of those came bundled as albums, or, more interestingly, the total cost of all that music. So let’s just ballpark it between $2,500 and $3,000 in music.
I subscribed to iTunes Match as soon as it debuted in 2011. I think that’s what? $25 a year? The nine years since then works out to an additional $225 for Apple.
I was an Rdio subscriber from February, 2011 until they shut down in November, 2015. At $10/month, that comes out to $570.
Yes, that’s a Google Buzz email notification about a tweet I posted saying:
Cancelled my @spotify membership after 24 hours. Nice product, but lacks discovery. Heading back to @rdio.
Again, searching my email archives, I found that I joined Pandora in July 2008 – back when the welcome email was still addressed from Tim.
I couldn’t determine the exact date I first became a paying customer, but I know I’ve been one continuously since at least sometime prior to mid-2012, which is the first record I have of my paid Pandora subscription renewing. Five bucks a month times ninety-two months is $460.
Once Rdio got acquired by Pandora and shut down, I switched to Apple Music. For a while I just paid $10/month for myself. But during the last few years it’s been a family play for $15/month. Regardless, let’s take the cheaper option and assume $10/month since December 2015: that comes out to a cool $500.
To date, that’s $4,755 I’ve legally paid for digital music.
At a minimum.
All of the above was paid to the giants of the industry. I have no idea how much more I’ve spent on one-off purchases to indie bands and labels that were more than happy to accept a few bucks via their website in exchange for a zip file of mp3s. Or the various live concert vaults I’ve subscribed to occasionally.
I don’t have the foggiest clue where that amount of money places me as a music customer. Surely not the low end of consumers? But I doubt the high side either. I’m guessing I’m somewhere in the upper-middle compared to what most digital natives have spent on music.
But my point is this.
I happily and enthusiastically paid for all that music. But now? Every time I see the $14.99 charge for our Apple Music family plan hit my checking account, I wince. I pay it begrudgingly because I feel like I have no other choice.
Let me be 100% crystal clear about this. The only reason I subscribe to Apple Music over Spotify or Tidal – or, hell, – Amazon Music or god-knows-what thing YouTube is currently offering, is because it’s the first-party, default service on macOS and iOS. The friction to use any other app that competes with a pre-installed, first party app on iOS (and increasingly macOS) is just too damn high. After a while I end up feeling beat down by a thousand UX papercuts and submit myself back to Apple Music and Safari and Mail.
Pretty much every six months, like clockwork, I re-activate my old Spotify account, pay for a month, and give them another try. And I’m not just starting from scratch with a blank library. Each time I try again I pay Soundiiz to import all of my Apple music (note the lowercase “m” because I’m talking about my purchased iTunes music, ripped mp3s, and saved Apple Music playlists) into Spotify. That way I can be sure to feel at home and that their recommendation engines have enough to work with.
And it’s great. In most places the Spotify iOS and Mac/web apps are so much nicer and easier to navigate and grok. I almost never find myself waiting an eternity like I do just for the Apple Music home screen to change from an empty, white screen to a slightly-less-empty, white page filled with blank album placeholder images, to finally a UI I can actually use. And I never have those moments where I’m on a cell network and Apple Music just. Never. Starts. Playing. Spotify is almost without fail fast and responsive. Even using the Plex iOS app while driving to listen to music hosted on my iMac via my home Comcast connection is way more reliable than Apple Music coming from their cloud. (Random: Like listening to music? Like how awesome Plex is? Definitely check out Prism.)
And while I love the idea of Apple’s human-centric approach to playlist curation, it just doesn’t work in practice. Spotify gives me vastly more and better recommendations for new and related music. Like my beloved Rdio of years gone by, Spotify is just far superior to Apple for discovery.
So, if Spotify is easier to use, is (arguably) designed better, performs better, is more responsive, and surfaces better content, why am I paying for Apple Music?
Like I said, it’s because Apple Music is the default.
When I use Spotify, it doesn’t matter whether I last opened the app two weeks ago or whether I backgrounded it two minutes ago while walking out the door. As soon as my phone connects to my car’s bluetooth, what happens? Ha. Why even bother writing this? We all know. Apple’s Music.app takes over and starts playing. Oh, and can we pause to admire how Music.app still can’t pick up from where it left off? In the best case it starts back at the beginning of the song that was last playing. In the more likely case it starts with the alphabetically first song in my library. Which means I’ve heard the opening whistle of Ace of Base’s All That She Wants roughly two-and-a-half million times. (Oh the irony. Just now as I googled for a link to that song, YouTube showed me this ad.)
Or how about if you ask Siri to play a song and don’t specifically say “…using Spotify” it goes straight to Apple Music even if you’re not a subscriber?
Initially, there were no 3rd party apps on iOS so of course Mail and Safari were the defaults. But then we got the App Store and suddenly there were tons of 3rd party mail clients and web browsers.
I wish I could find the quote I’m thinking about. I honestly can’t remember if it actually came from Apple on-stage at the iOS 7 reveal or if it was just repeated a bunch by pundits, but the idea was that pre-iOS 7 everyone was still getting used to mobile software. But with the big redesign (The Great White Flattening?), “the trailing wheels are coming off“. It could now be assumed that users know how this stuff works and should be trusted and given more powerful options. At that time I thought, finally, maybe we’ll be able to set a new default mail client.
But, no. Apple pivoted to banging the drum of Privacy. And I get it. If everyone just willy-nilly installed the Gmail app without thinking, and if Apple made it easy to use the Gmail app on iOS instead of artificially crippling it and essentially forcing people to their first-party Mail app, Google could probably vacuum up even more of our personal data. (Slightly related: remember how long the original Google Voice iOS app sat in review?)
But now? Now when you see that decision standing alongside the rise of heavy-handed, in-your-face, dark-patterned, growth-at-all-costs, rise of Apple services? How can anyone not be cynical and assume these restrictions are anything less than yet another push to squeeze an additional monthly penny out of customers?
It all just leaves a bad taste in my mouth. From the ban on default apps, to the constant Apple Card promotions, the Apple News push notifications, pretty much everything they’ve released in the last few years. It just feels fucking desperate and greedy. I’m completely paraphrasing comments I’ve read elsewhere made by people smarter than myself, but the Apple of old used to earn our money by creating products we loved. Now it feels like they take our money by locking us into services we have no choice but to use.
And back to the original topic and title of this post: I now give Apple my money begrudgingly. It pains me. And, god help us, with today’s news about Apple cutting sales expectations because of the coronavirus, I can’t even begin to imagine what the growth hackers at Cupertino are going to rain down upon us next.
Goddammit, Apple. I’m in your corner. We’re all in your corner. Don’t fuck it up for a slightly higher stock price.
Postscript
I know this post meandered all over and was not as well backed up and supported as it should be given the claims I’m making and the level of vitriol I’m spewing. (I’m typing this in a dark bedroom waiting for my four year-old to finally fall asleep.) So, instead, let me just refer you to Michael Tsai’s website – who is basically the Apple dev community’s lead champion at assimilating all the disparate opinions on whatever news story or technical tidbit currently has us in a frenzy. He collects the facts and puts them together way better and without all the emotional garbage that I inject into everything.
The more men are freed from privation; the more telegraphs, telephones, books, papers, and journals there are; the more means there will be of diffusing inconsistent lies and hypocrisies, and the more disunited and consequently miserable will men become, which indeed is what we see actually taking place.
I read The Kingdom of God Is Within You in college. I think I was too young at the time to fully digest it – for it to have the impact on me that it has had on others. Nonetheless, Tolstoy’s ideas have stayed with me in the seventeen years since then. Particularly the bit I quoted above. It seemed prescient at the time during the post-9/11 run-up to the war in Iraq when every news organization collectively lost their minds and got drunk on the power they found by turning up the volume, channeling fear, and scrolling sensationalized chyrons 24/7.
And now in 2020? There’s no need for me to spell it out. It’s all become exponentially worse in just a few short years.
Other than my unhealthy addiction to Twitter (which is clearly a huge part of our problem), I reached the point two or three years ago where I would only log in to Facebook once every few months. But I would never post anything. My Instagram account was made private long ago after a bunch of creepers started adding comments to photos of my kids they came across because I had (stupidly) tagged the images with the state park we were visiting.
Once all the old-guard tech companies realized there was no money to be made from instant messaging, they shut those networks down. Everyone I cared about migrated to text messages. I poured one out for Adium and haven’t even launched that app since 2016.
All of my close friends and family share exclusively through iCloud photo albums. (Oops.)
By the time 2020 arrived, I had sort of made peace with the idea that all those hundreds of friends I had on Facebook weren’t really very good friends after all. And I was honestly sad at the thought of no longer seeing my high school classmates’ kids grow up in photographs – even though I hadn’t seen or spoken to them since the day before graduation twenty years earlier. Except for that one click to confirm a friend request, of course.
As far as I was concerned, I was done with Facebook. And mostly Instagram, too. A quick look at my 1Password shows 842 website accounts. How many of those have I logged into in the last five years? How many of those services even still exist? I just assumed Zuck’s empire would become one more abandoned piece of my personal online history. And I was content to let my accounts lay dormant forever.
I’ve thought a lot about that story over the past twenty days. And in the course of writing this blog post I’ve taken the time to re-read it, gather my thoughts, and try to pin down exactly what it is that I find so objectionable. So anathema.
And I can’t do it.
It’s not just one thing. Or even a final straw. It’s all of it. Everything at once. An entire decade’s worth of shit, greed, hubris, and billions of people (myself included) who are both the perpetrators and victims.
What I think affects me the most is that I know how these things are built. And it infuriates me. I’m a developer. I’ve also worked in Product. And I’ve worked in Marketing. To a degree, all of these social networks are founded and grown organically. And perhaps they even become unicorns organically, too. But at some point we all have to admit that they do not continue to grow unbounded, continue to make disastrously poor, costly, and harmful decision after decision without morally bankrupt leaders and equally indefensible low-level workers purposefully and consciously choosing to do the wrong thing all in the hopes of upping engagement a sliver of a percent so they might earn one extra dollar.
Real people – every day – are going to work and continuing to build these systems. They plan the sprints. Write the code. Review the copy. And push to production. They speak at conferences and post on Medium about the hard problems they are solving.
Fuck all of my old Silicon Valley friends who remain at these companies and participate in this fraud just to get one more stock grant.
But I’m done. As of last week my accounts are closed. (Well, except for Twitter. I am a professional hypocrite after all.)
This is just a decision I’m making for myself. For my mental health. And to continue being morally OK with existing online. I’m not advocating for anyone reading this to close their accounts, too. If you find a particular social network beneficial, go for it. The world is on fire, and we can all use happiness wherever we can find it.
This is just my choice. And I’m not even anywhere near the first person to come to it. But already in the last week I feel like a weight has been lifted.
Next
So, what comes next?
For me, that means continuing to interact with the same people I already care about by sharing and posting even more with them now that I’m not feeding the machine. And I’ll do that by owning my own platform.
For me, that means blogging with WordPress because that’s the publishing tool I’m most comfortable with.
I’ve already setup a new website to replace Instagram and to a lesser extent Facebook. It’s public facing, but I’m not going to share the URL here. It’s just for friends and family. If you happen to find it, then I hope you enjoy the many photos of my lunch as well as my kids being annoyingly cute.
Of the accounts I closed, Facebook and Instagram are the only two I care about preserving my history. Fortunately, both services offer comprehensive data export options to let you get a copy of all of your data in both human readable and machine readable formats.
I’ll leave the exact instructions as a google exercise for you, but in a nutshell the process is this…
Export your data. You’ll be emailed a link to a zip file.
Create a new WordPress blog somewhere.
Run the PHP scripts in this GitHub repo.
Profit.
The two scripts (one for Facebook, another for Instagram) will crawl through your exported data and make some (I think) clever decisions about what data to import and how to import it in a blog-friendly way. The result will be a blog with all of your old photos and videos, along with captions, and (optionally) location data inserted chronologically with the same date/time that you posted the original content.
One extra-special thing about this script I want to point out is that I also approached it from the point of view of a parent. I want to be able to share this new website with friends and family – many of them not the least bit tech savvy who frequently call me for help because they’ve forgotten their Facebook password…again.
So the last thing I want to do is lock all of this content behind yet another account they have to remember.
But at the same time I don’t necessarily want detailed personal info about my kids just floating around online before they’re of age to consent to that themselves.
So, like I said above, importing the location data attached to your old content is optional. But also, the script allows you to define a list of replacement words. The idea being, I added my kids’ names to the blacklist in settings along with a replacement. Then, when the script imports everything, any post caption containing names (words) like “Trevor” or “Jacqueline”, will be replaced with “T” and “J”.
This allows me to maintain the context of what I originally posted and/or captioned my photos with without being too revealing. If a stalker is determined to find out the names of my kids, there’s nothing I can do to stop them. But that doesn’t mean I have to make their identities easily googlable.
Here’s what the finished product looks like…
It’s every Facebook and Instagram post I ever made that included a photo or video, on my own domain, set to the date and time they originally appeared. It’s almost like Facebook was just a bad dream.
Furious Conclusion
So that’s my small contribution to make things better. It likely won’t matter. But it does give me some relief to have done something. Anything.
I’m filled with rage and despair and also just sad thinking about what we in the tech industry unintentionally unleashed upon the world – and then willfully made worse through greed and arrogance.
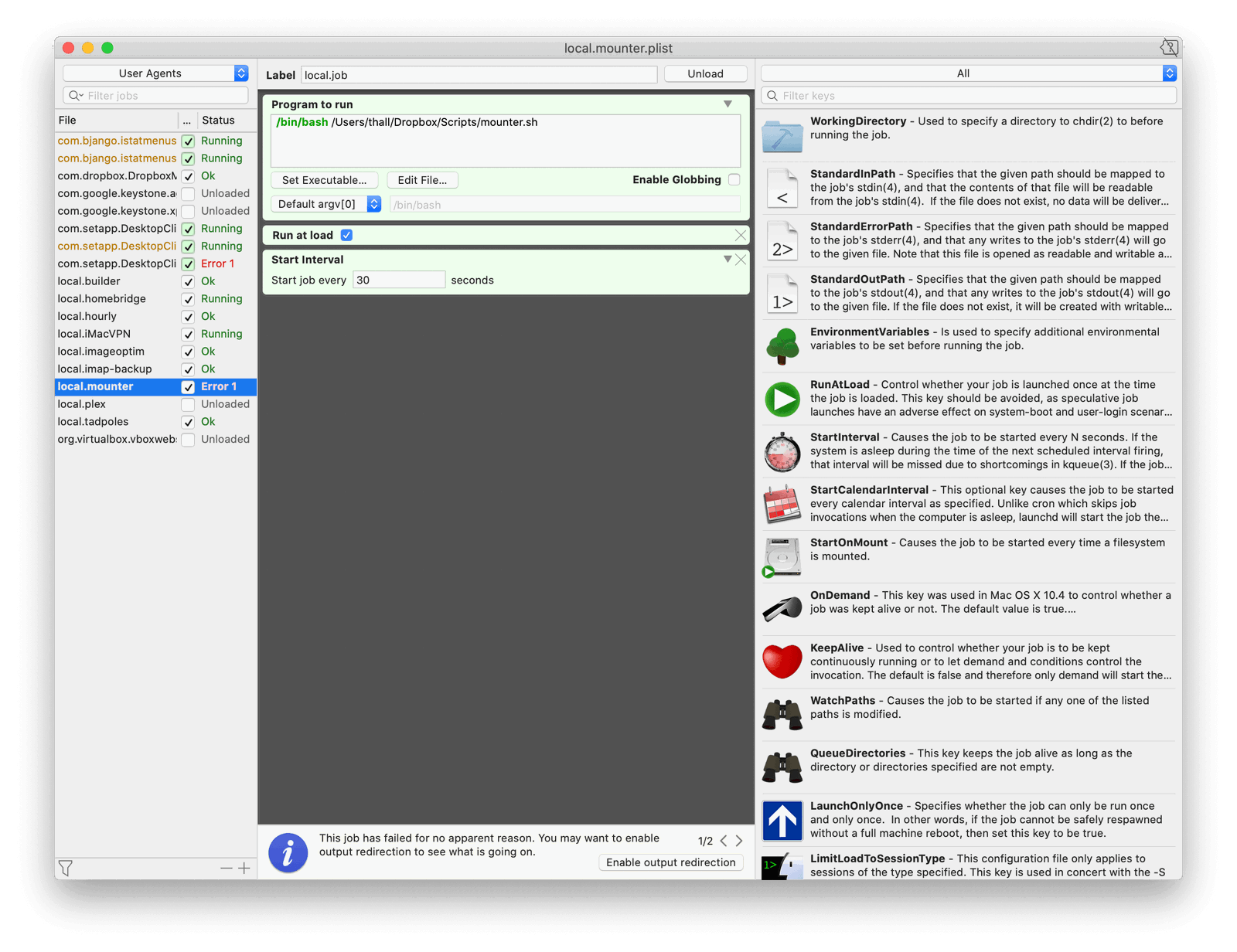




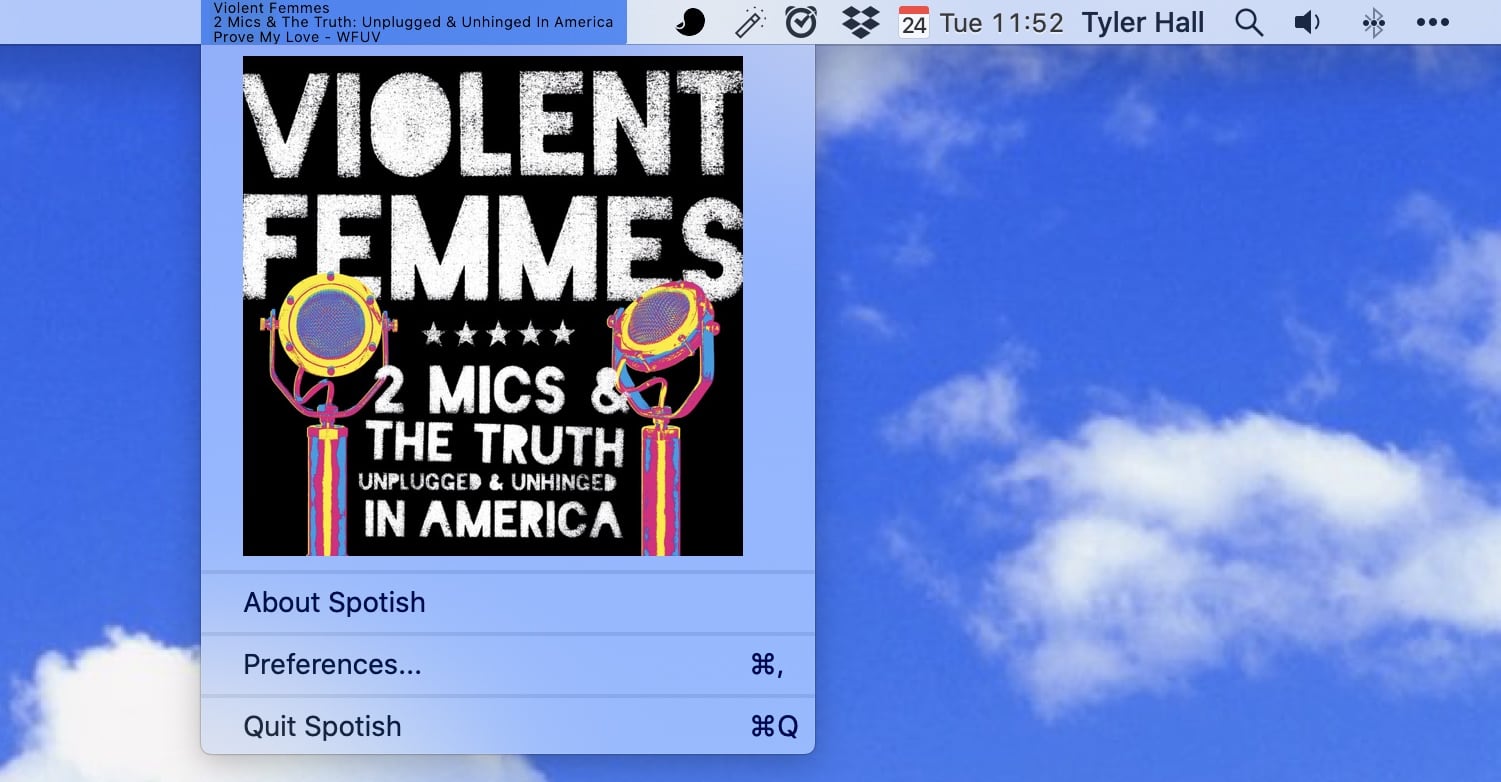
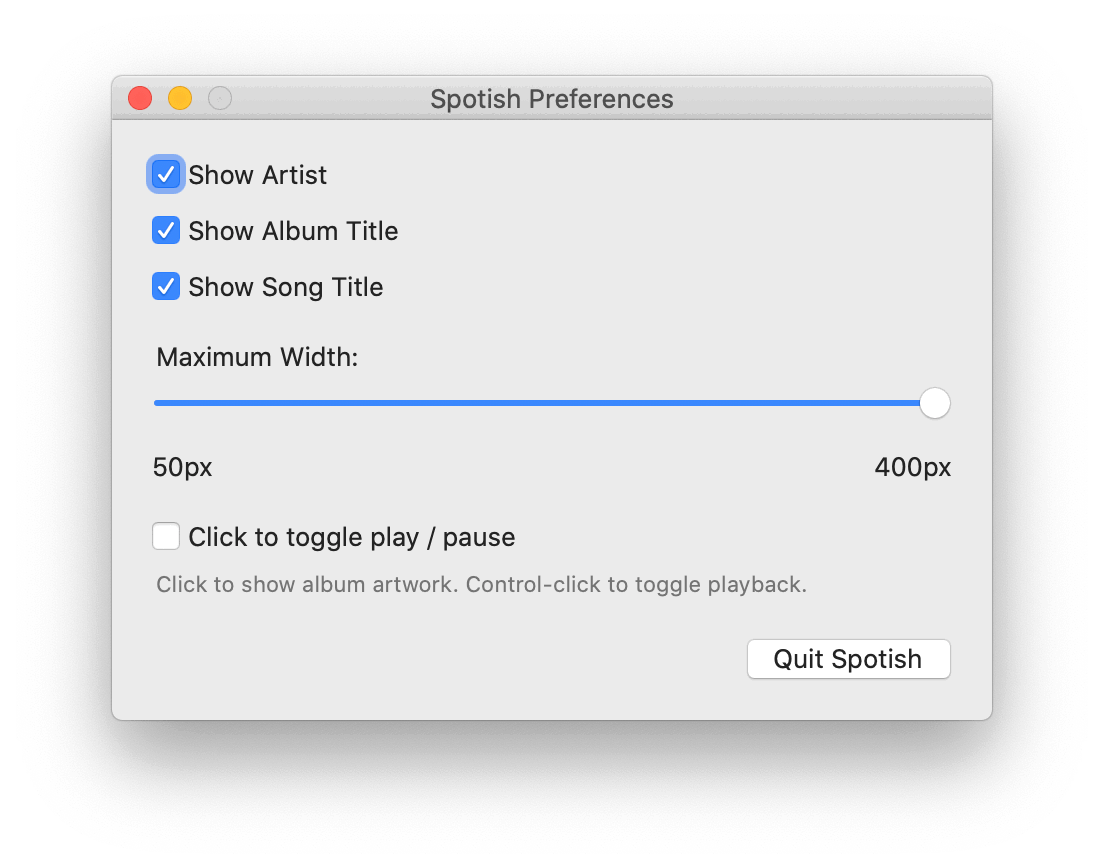
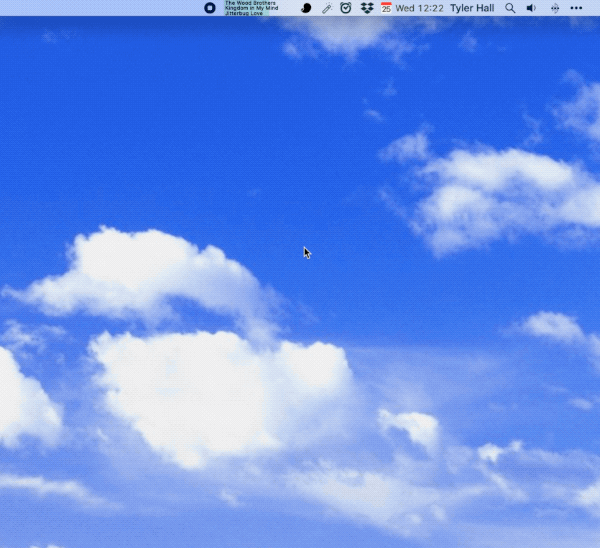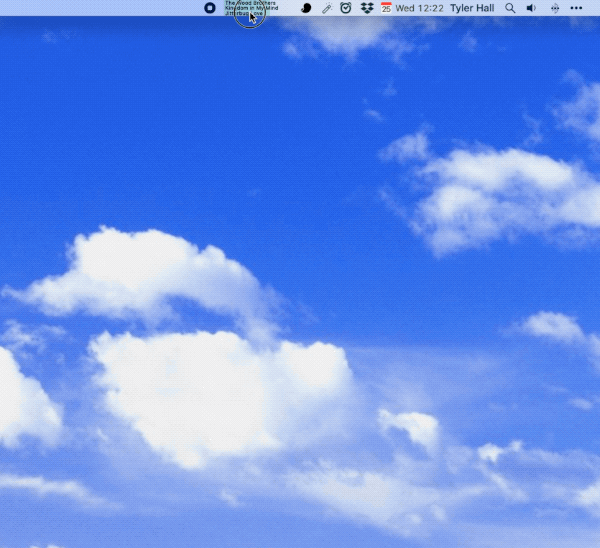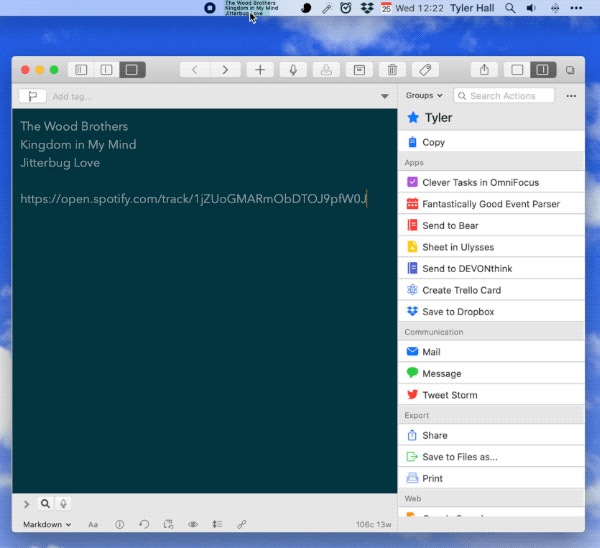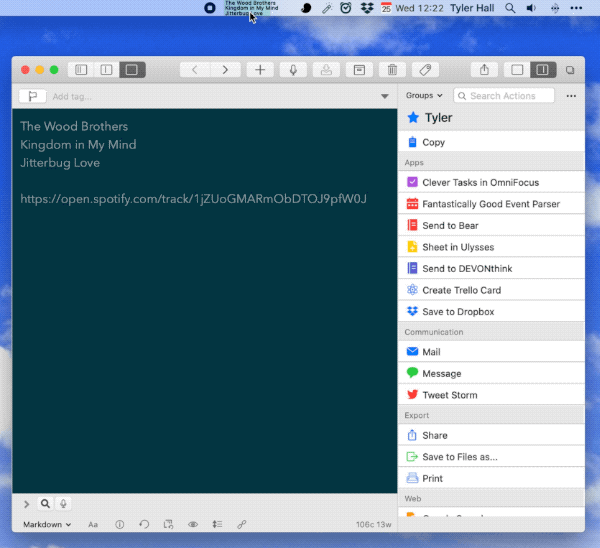
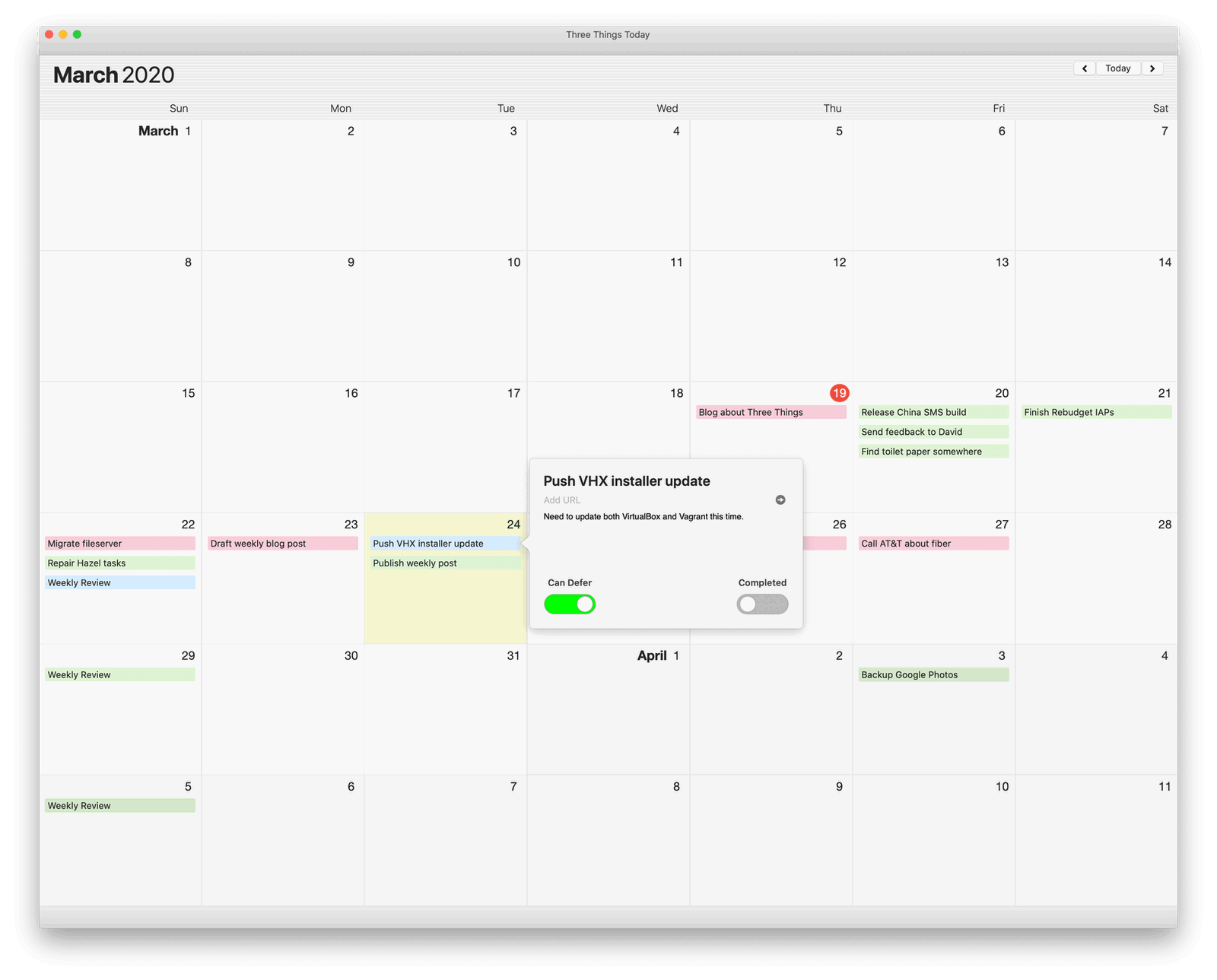


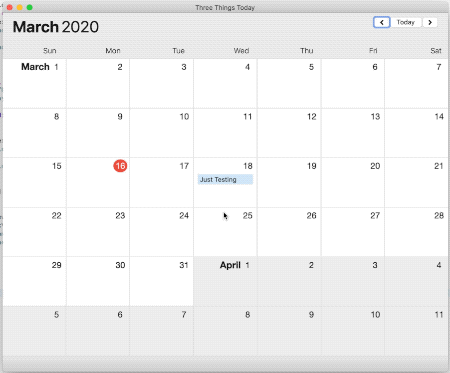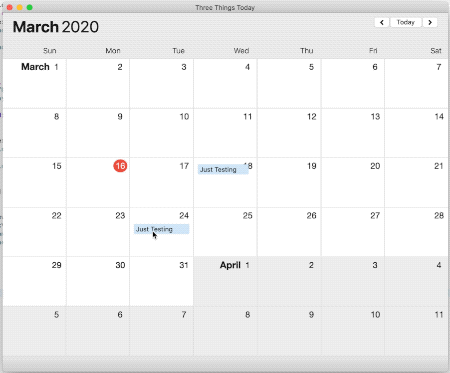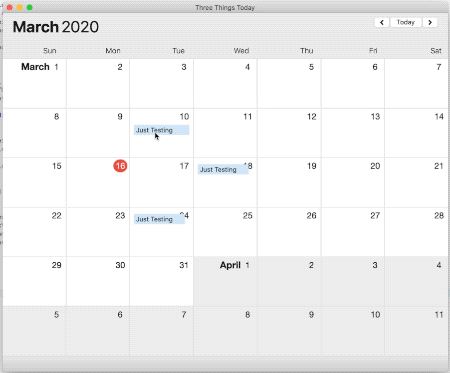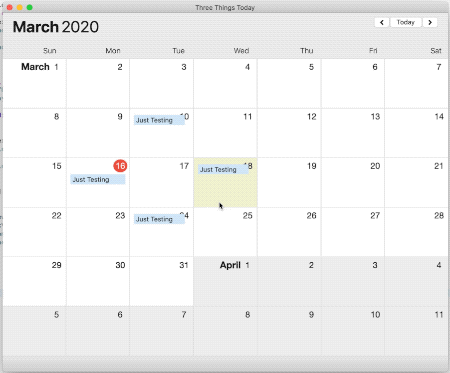
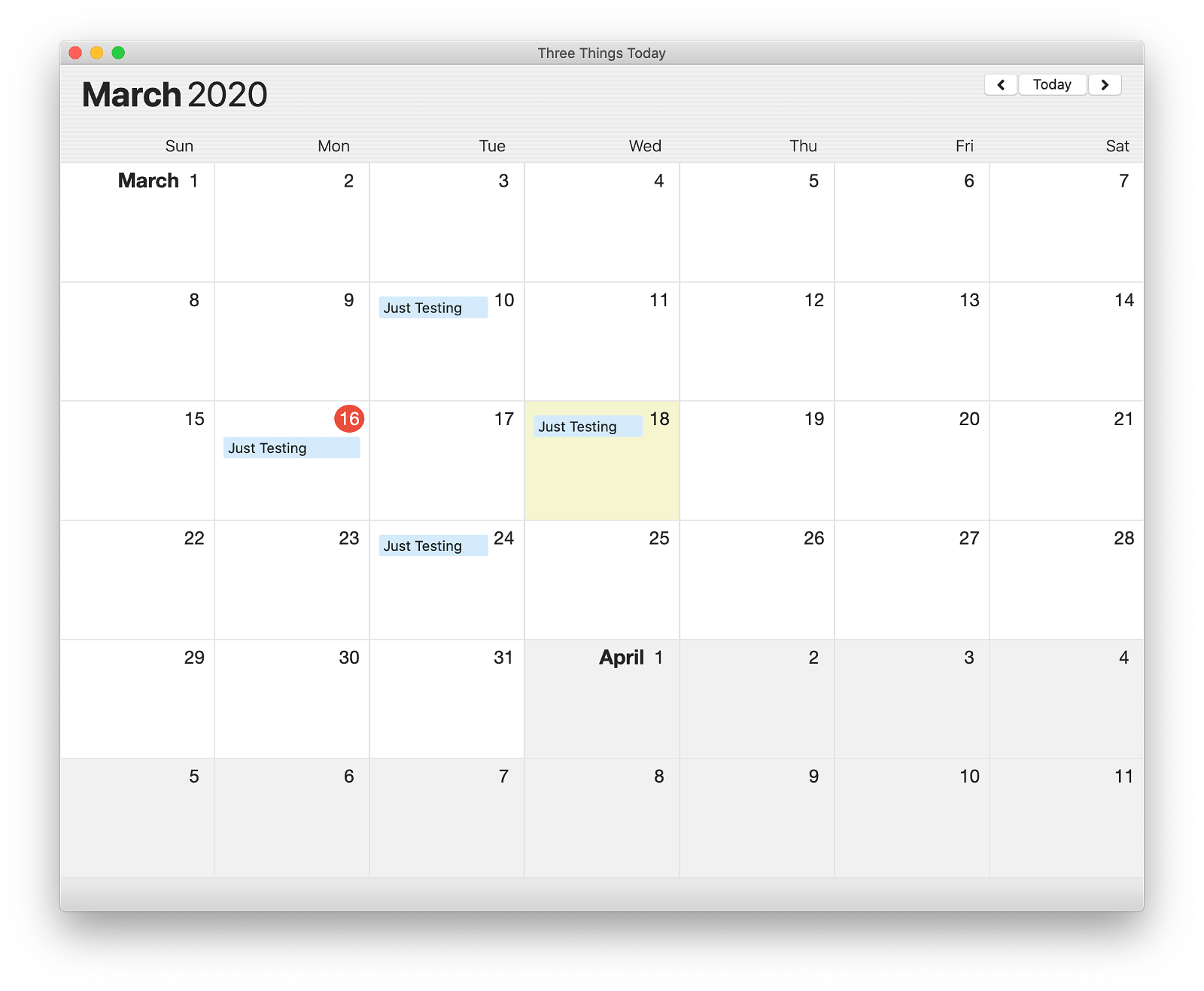
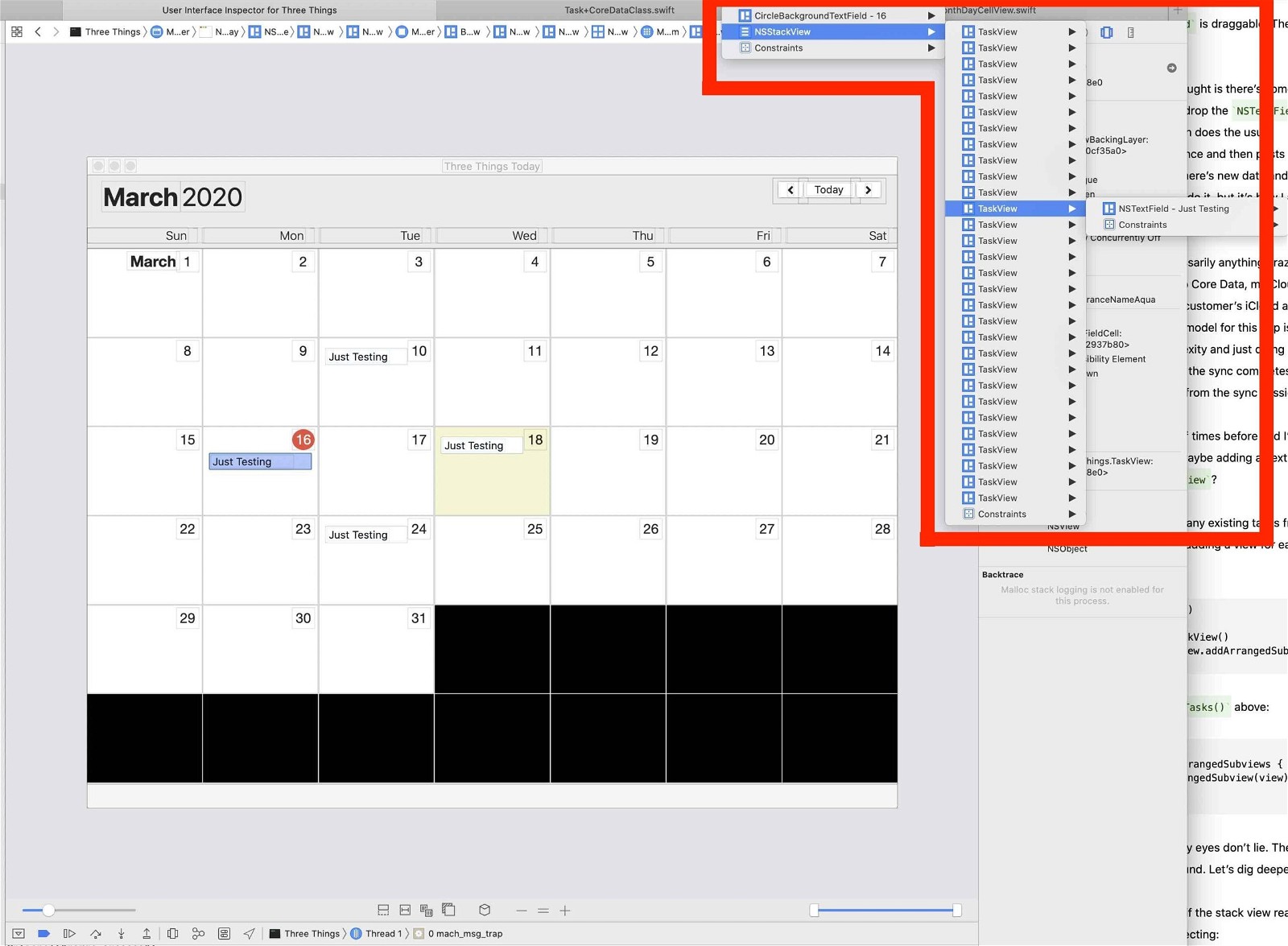
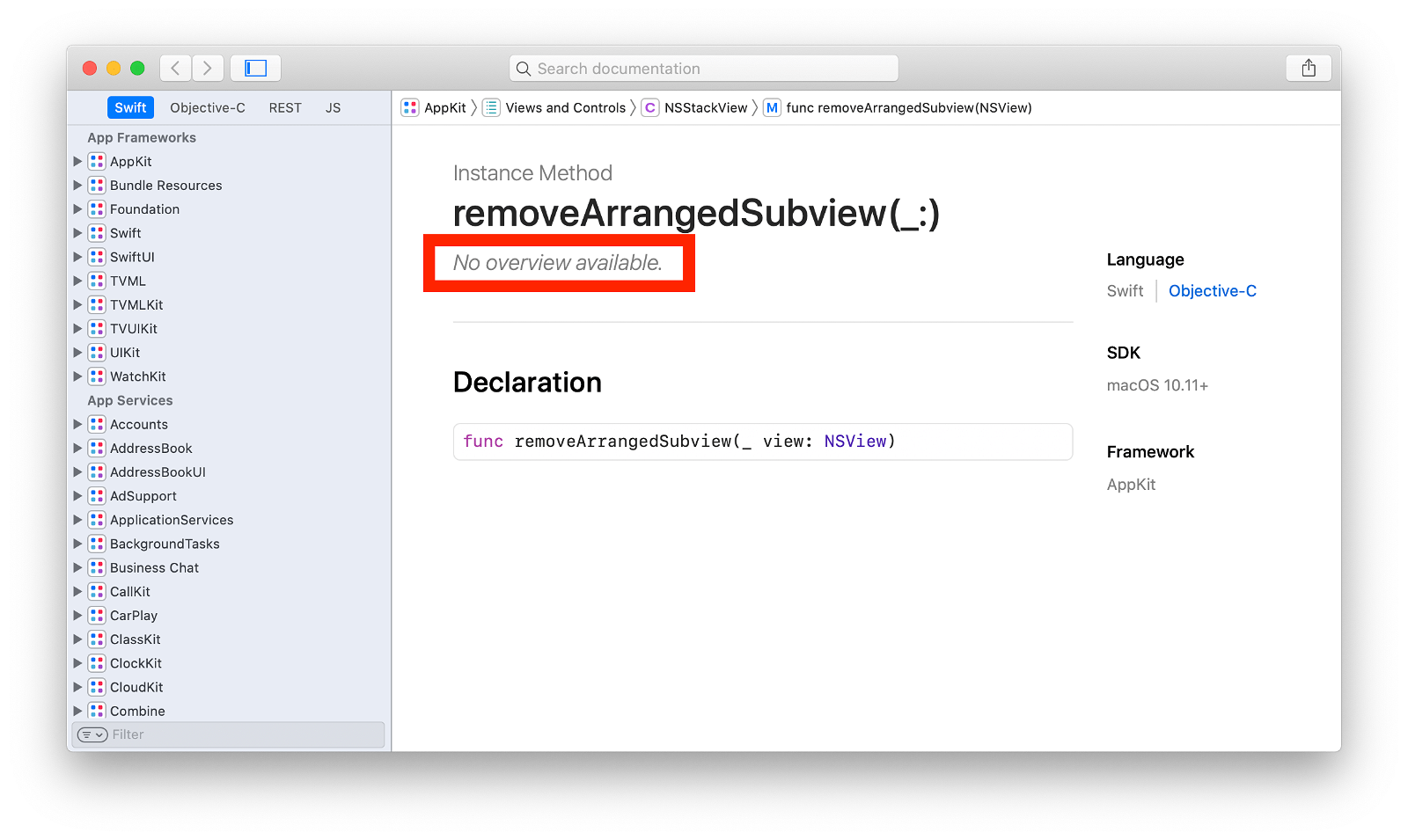
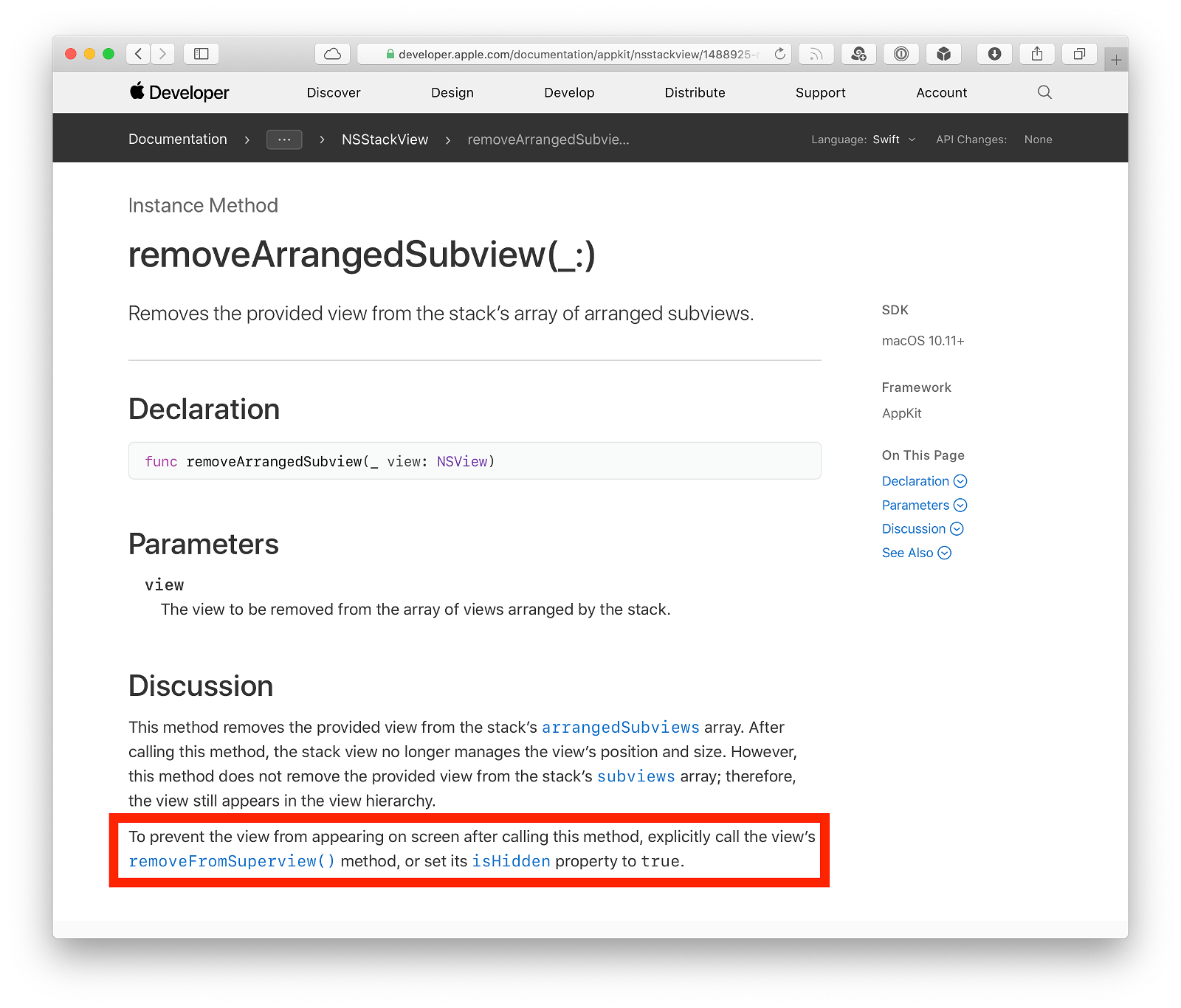


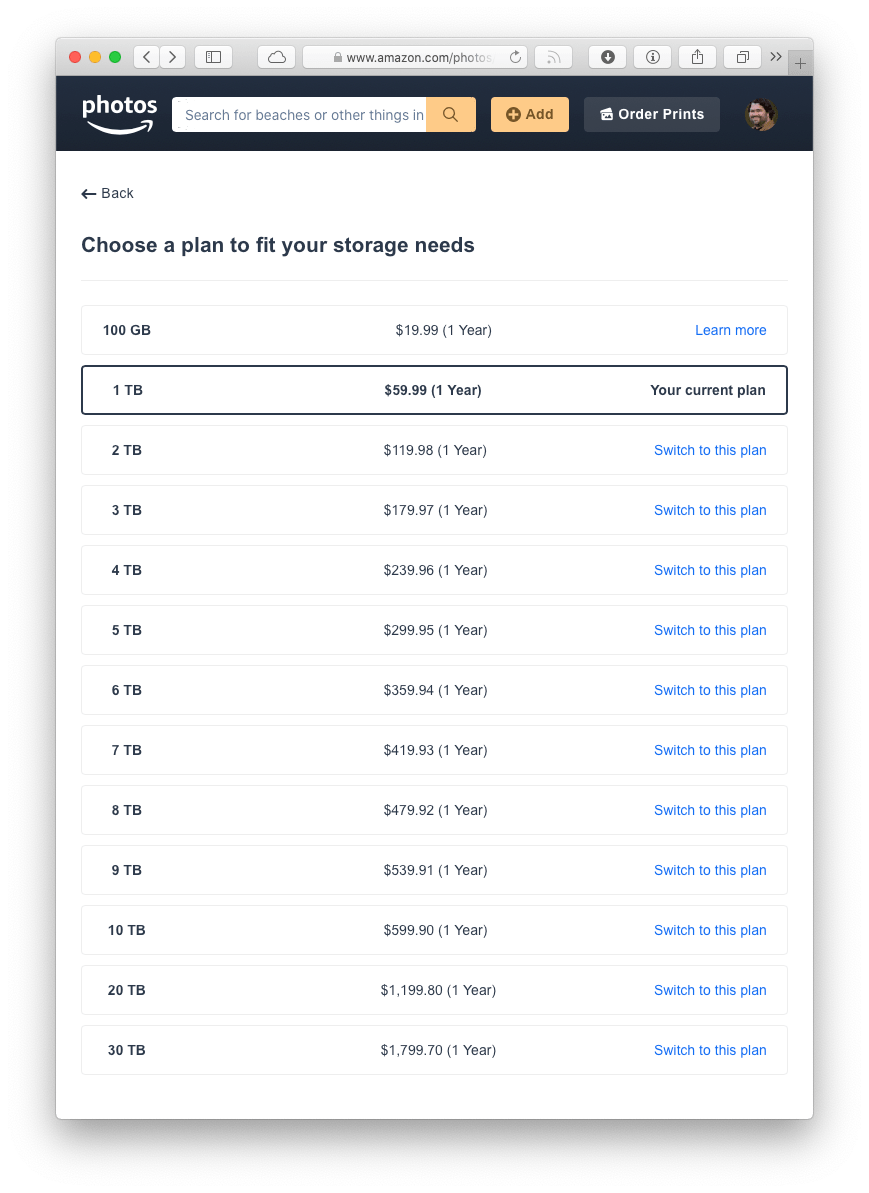

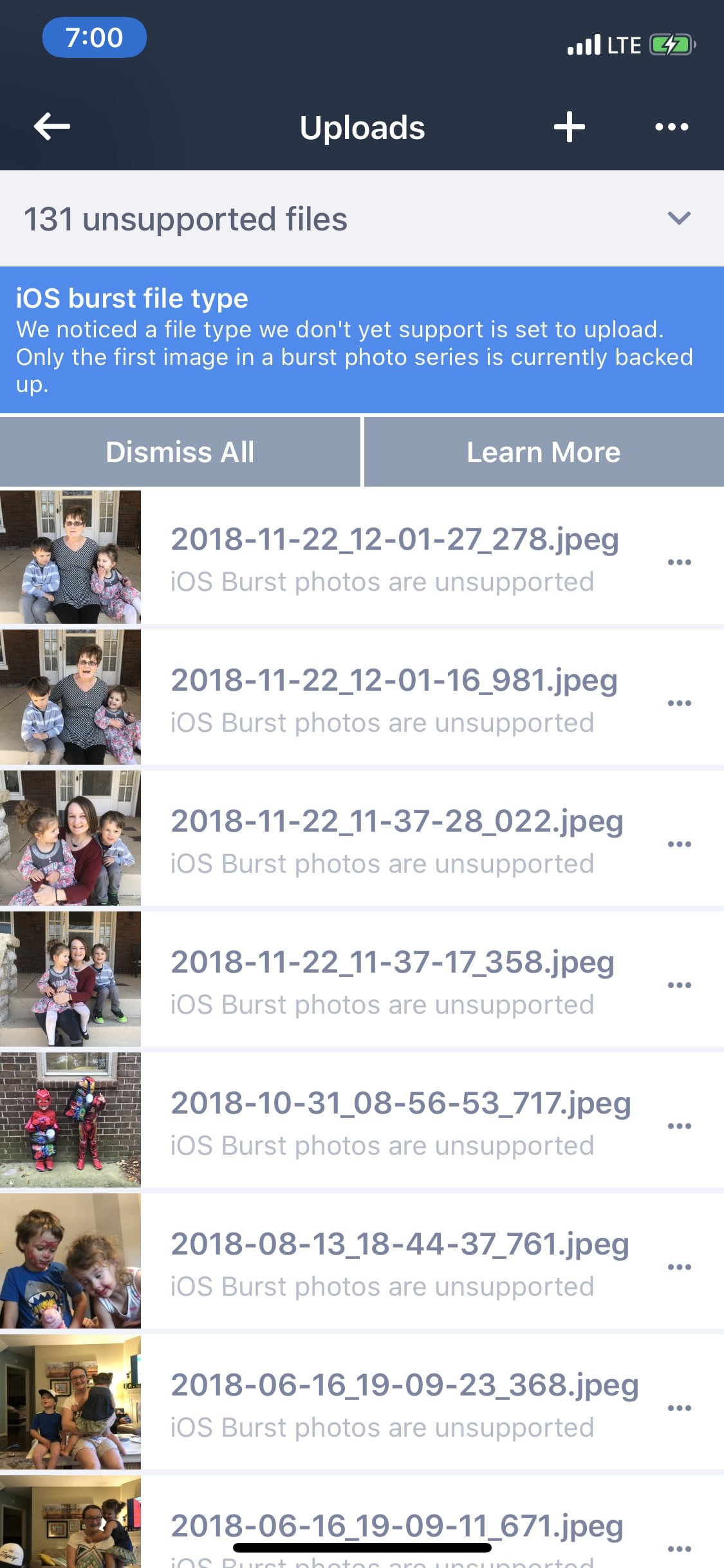
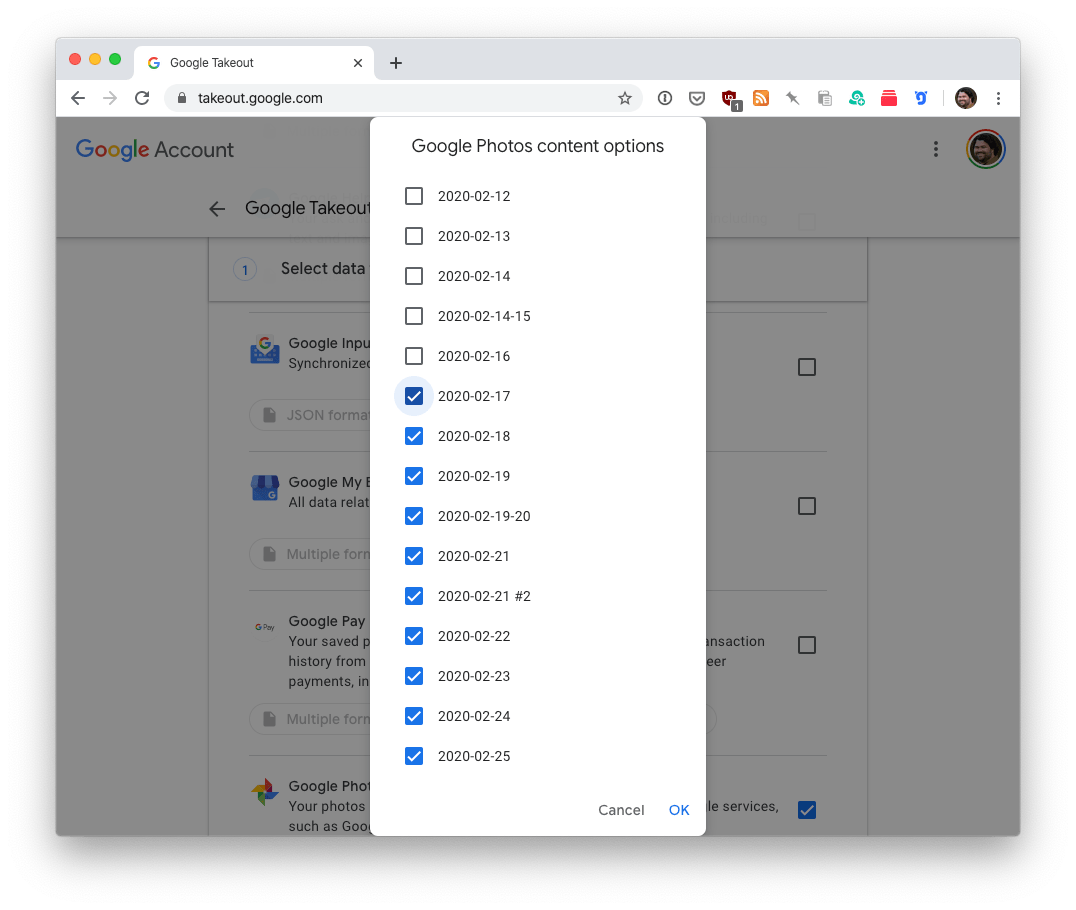
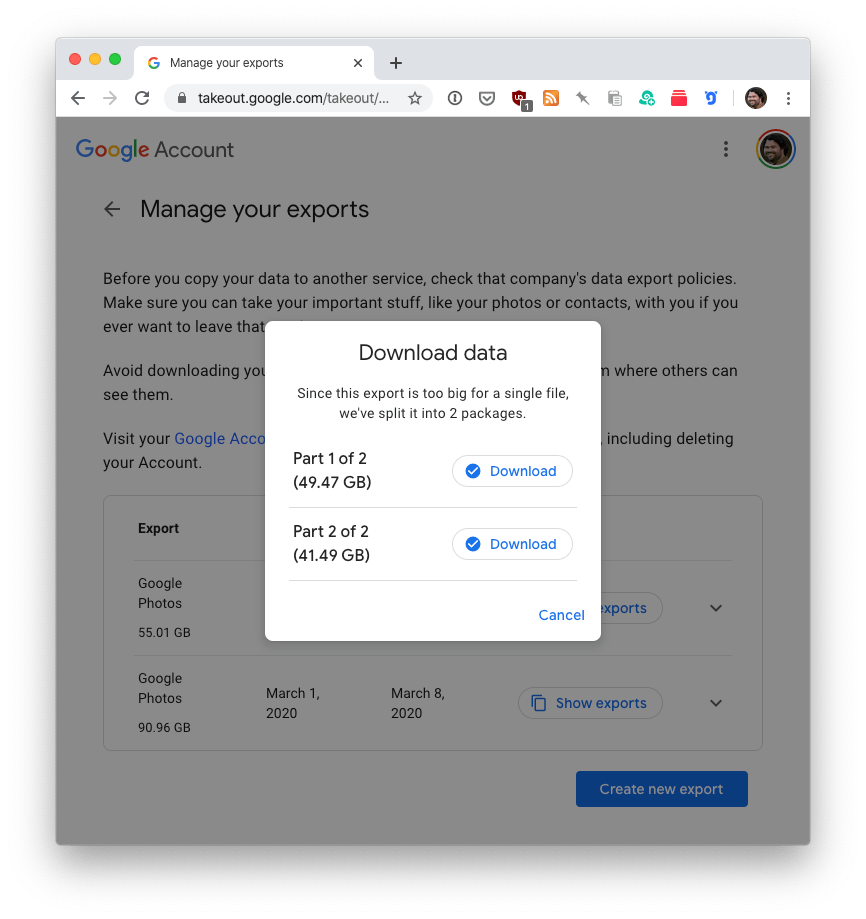
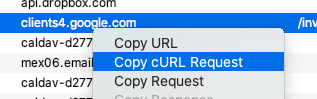
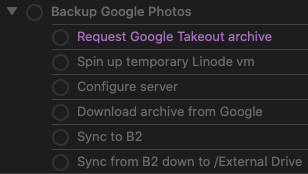
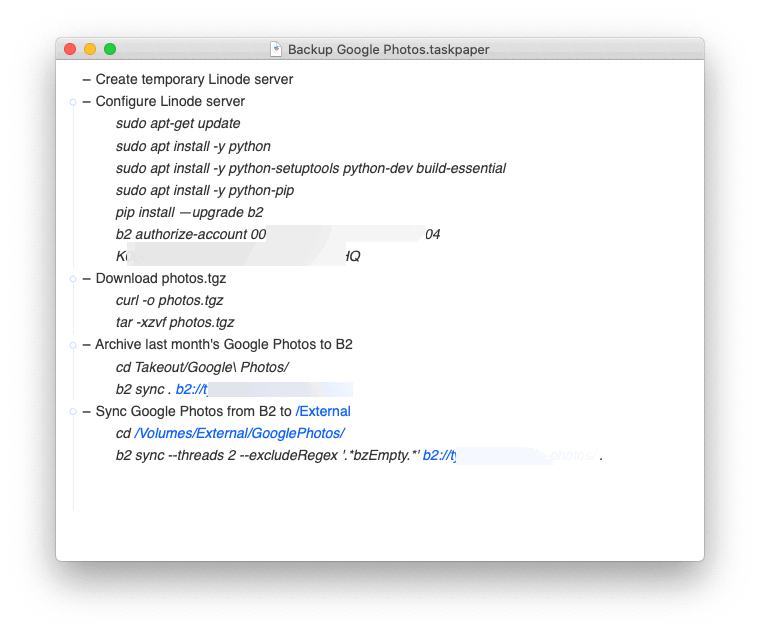
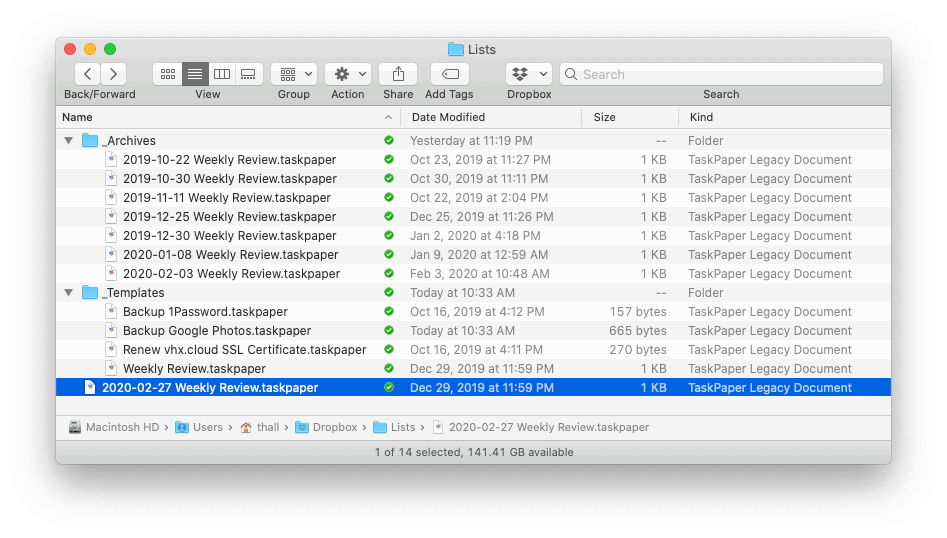
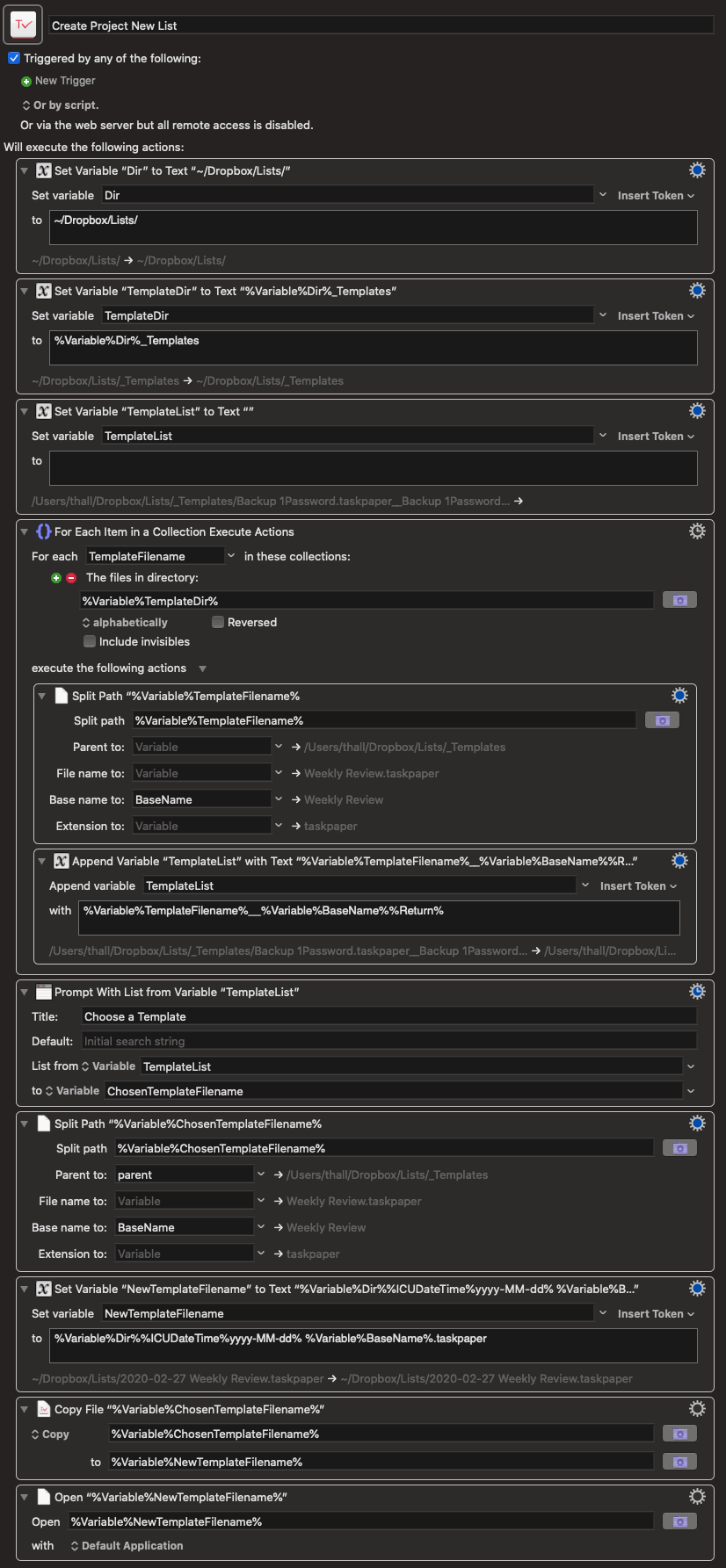
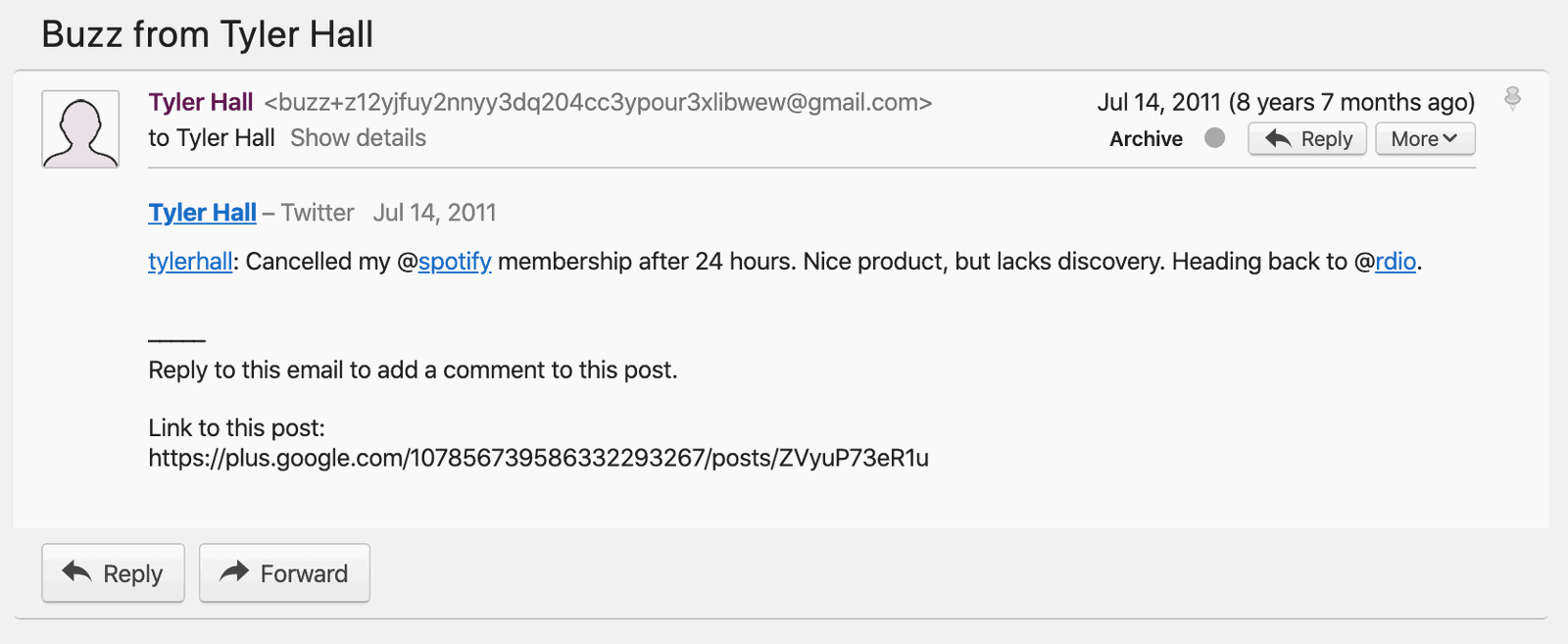

{kind=link}