Two of the topics I’ve written about the most on this blog are backing up your data and also photography – not professional, artsy photography, but more in the sense of your family’s photo and home video library. I’m a huge nerd for these topics. Part of the reason for that is my own obsessive personality traits, but also because of my affinity for nostalgia and history. My life, to a certain degree, is documented through the literal data I’ve created over the years. And the lives of the people I love are likewise documented through the digital archives I keep. So when those two topics intersect, holy cow do I ever proudly fly my geek flag.
The first post I ever wrote about backing up my data (posted to the blog of a former employer) made it to the front page of Digg back in May 2006.

There’s no need to rehash how much things have changed since then. I could go on and on about how the backup options available to consumers have evolved as well as how we’re simply generating exponentially more data. In fact, I do go into all of that here and here. Instead, I want to specifically talk about how I’m managing my family’s photo and video archives from two perspectives:
- Purely from a data safety perspective. That means ensuring nothing ever gets lost.
- And also from a usability point of view. Unlike other types of long-term data storage, the whole point of keeping your photos and home videos safe is to be able enjoy them. If they’re only stored on Blu-rays or magnetic tape drives kept in a bank vault, that kinda defeats the purpose.
The last time I wrote about this topic I thought I had everything figured out. And for a while I did. But it (surprise!) turned out that the Rube Goldberg machine I had created using rclone, rsync, and the Google Drive API as a workaround way to access my Google Photos, was a little too fragile. My aim back then was to make as much of the process as automatic as possible. In hindsight, I think that was too lofty a goal. Over the last nine months I’ve settled on a more manual, monthly backup strategy that I’ve found to be a good compromise. It Works For Me?
99% of my family’s photos and videos come from mine or my wife’s phone. We’ve had two DSLRs over the years. And even bought a nice camera specifically for when my son was born at the recommendation of Shawn Blanc. But they’ve all fallen by the wayside as camera phones have gotten so damn good. (Also, something something about the best camera is the one you have with you.) So, nearly every photo we take comes from one of our iPhones.
The other remaining one percent? That comes from photos other people take of our kids and post to a shared iCloud photo stream. I did have a decent system in place for backing those up, but then, well, shit. So I’m still not sure what to do about them anymore 🤷♀️.
Anyway, my family’s photo and video collection is currently weighing in right at one terabyte. For a long time I managed to keep it all stored and organized in Dropbox. I even wrote an app specifically to help with that. (As well as a book I never finished writing.) Eventually, though, that became untenable and I bit the bullet and switched to Google Photos. And Google pretty much solves the usability aspect of this puzzle for me. You can read that linked post for the reasons why I think it’s an incredible product.
Both my phone and my wife’s phone backup automatically to Google. A year or so after we made the switch, Google debuted partner accounts that let you automatically share your library with one other person. That’s awesome – and something I think Apple is sorely missing. But given that my wife and I had already settled on a solution that worked for us and also that having a second Google account involved would complicate the backup process I outline below, we still use the old trick of having the Google Photos iOS app signed into my account on both our phones.
So, that’s what needs to be backed up in a safe and sensible manner: 1TB of data stored in Google’s cloud. How do I go about it? I’ll tell you. But first…
Let’s talk about Amazon Photos and the cost of the cloud
Amazon debuted their Google Photos competitor in 2014 (I think). I gave it a brief try around 2015 or 2016, but I was very much underwhelmed. I remember it being decidedly not good and wrote it off. But late last year, for reasons I don’t really remember, I thought I’d take another look. And you know what?
It’s really good. Like, really, really good. Light years ahead of what I remember first trying.
For the last two years I’ve been looking towards the future and the ever increasing size of my photo library and hoping for a way out of Google. I certainly worry about the privacy implications of willingly paying Google to slurp up even more of my private data, but, meh. I don’t know of another alternative, and (for now) I’m willing to make the tradeoff given the benefits Google Photos offers. My biggest concern is the expensive brick wall I’m going to run into in the next year or two when I estimate I’ll cross into the next storage tier.
As I said, I’m currently using 1TB of data. My current Google One storage plan is $9.99/month for 2TB. That’s the same pricing as what Apple offers with iCloud. But what happens when I reach 2TB and 1 byte? The next option is 10TB of storage for $99.99/month.

Uh, that’s quite a jump. And I’m not even saying the price is unreasonable. If I had 10TB of data to store, I’d be fine paying that much. (Even B2 would cost $50/month.) And, to be fair to Google, at least they offer the option. Apple doesn’t even offer a higher iCloud storage tier than 2TB. When my family maxes that out? I guess our phones will just stop working?
But even as quickly as my data needs are growing, it’ll be a long time before I can justify $100/month. And so that’s why I decided to give Amazon Photos a full-on, complete, all-in try. Take a look at their pricing:
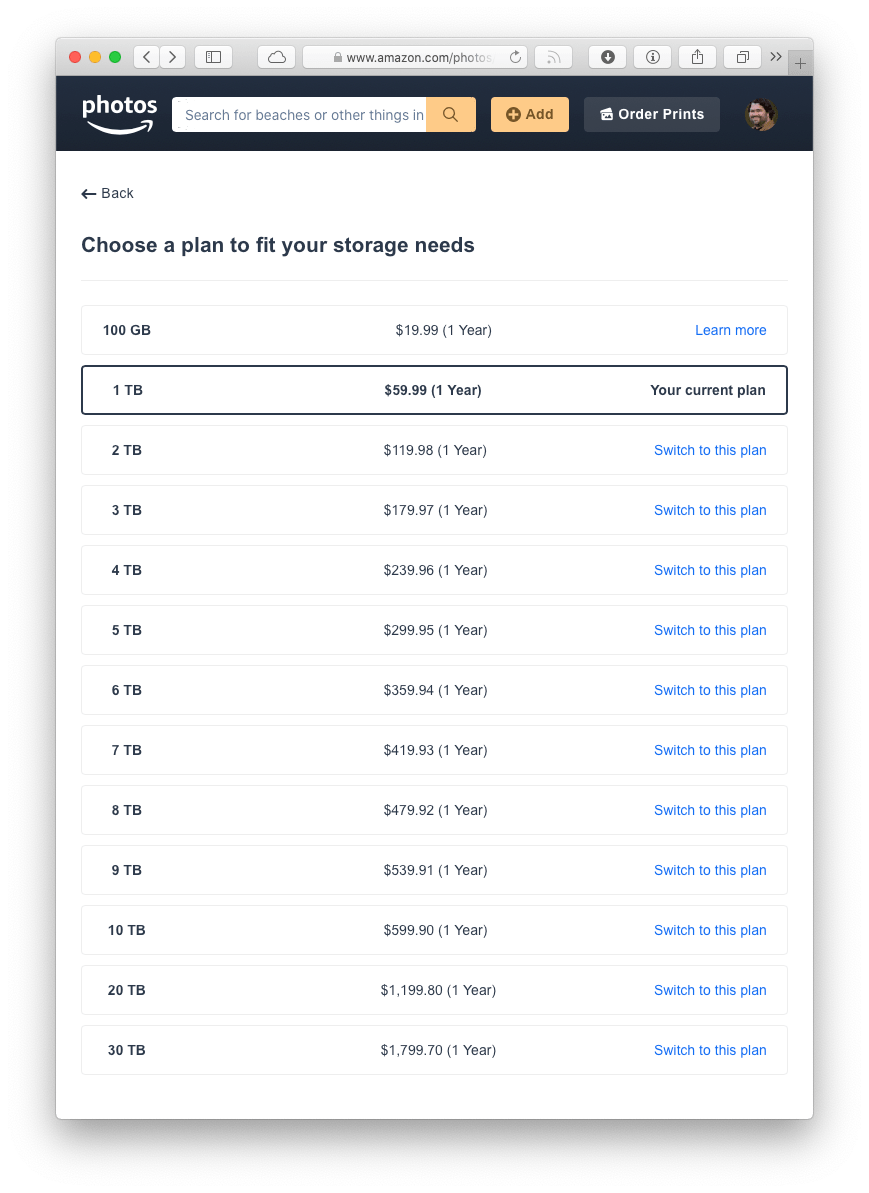
(Oh, and I should point out a bonus about using Amazon. If you’re a Prime member, you can store an unlimited number of full-res, original quality photos and they don’t count against your quota. So, the extra storage space you’re paying for only needs to cover your videos. That can be a potentially huge cost saver.)
I’m assuming Amazon is more concerned with purely making a profit on their storage costs because they have plenty of intermediate tiers that reasonably increase in cost as your storage needs grow. In my case, going one byte over 2TB with Google would be $1,200 a year for 10TB. Amazon would only be $180 for 3TB. And so with $1,020 on the line, I wanted to give Amazon Photos a fair shake and see if they were a viable alternative.
Spoiler: they’re not. At least not yet. But it was so damn close.
Let’s start with the good parts.
Amazon’s app, while maybe not as pretty as Google Photos, is far more functional and snappier to use. What I mean is, when I look at Amazon Photos from an iOS developer’s point of view, it appears to be built with, you know, UIKit.
Google Photos? I get the horrible feeling they’re attempting some shared codebase, cross-platform, UI framework shenanigans that only the engineers at a multi-billion dollar corporation intent on solving “hard problems” think they can pull off. Like pretty much all of their iOS apps, it feels completely foreign on the platform. But UX issues aside, it just doesn’t perform as smoothly. When I scroll through a long stream of photos, I can just feel all the layers of indirection and architecture they’ve built working furiously just to be able to display an image loaded over the network.
Amazon on the other hand – their shit is fast. It feels fluid and responsive in a way that only truly native apps do. Even on a mediocre LTE connection, images scroll on screen just as fast as I can scroll to them. The same is true about both of their web apps. It feels like Amazon is using a bunch of <img> tags inside a <table> (not really, of course). Meanwhile, Google is playing fast and loose with the DOM to reimplement scrolling from scratch for reasons only god knows why. I hardly ever see any blank / placeholder images with Amazon while I wait for the network to catch up. Google on the other hand…
For all of Google’s early leadership to help speed up the web…
After a bit of looking, Marissa explained that they found an uncontrolled variable. The page with 10 results took .4 seconds to generate. The page with 30 results took .9 seconds. Half a second delay caused a 20% drop in traffic. Half a second delay killed user satisfaction.
This conclusion may be surprising — people notice a half second delay? — but we had a similar experience at Amazon.com. In A/B tests, we tried delaying the page in increments of 100 milliseconds and found that even very small delays would result in substantial and costly drops in revenue.
the Google Photos app just feels slow in comparison.
Next up. Amazon’s sidebar filter. Oh. My. Goodness. It ticks my nerd checkboxes so hard.

With Google Photos you just have a search box. That’s it. And I get it. Google is built around search. The idea is to just type what you’re looking for and Google will give you that. And it works.
Until it doesn’t. Because it’s a black box, you have no idea if Google is interpreting your query correctly. There’s no documentation. No real search syntax to reference. You just have to sort of blindly experiment and hope Google understands what you’re asking for.
And, sure, Amazon has a search box, too. But being able to literally see the number of photos across all of the data points and categories Amazon has grouped your library into, and then being able to mix and match, sort and filter them live – until you’ve narrowed down to exactly what you need – is so incredibly refreshing and a delight to use.
The last super awesome feature I’ll highlight is a trend in consumer software that drives me absolutely up the wall. And that’s lack feedback when something goes wrong.
In my day to day life, Apple is by far the biggest offender. Almost daily, something iCloud or otherwise network related will fuck up on Mac or iOS, and the UI will just sit there with a dumb grin on its face like nothing is wrong. There will be no error message or any sort of actionable feedback about what went wrong. They’ve stripped the UI of so many progress indicators that often times you have no idea if anything is actually happening or if your task has just silently failed. Or, worse, there will be a progress indicator – but in the case of Photos.app on macOS – when you export a video it will remain at 0% for minutes upon minutes with no progress shown. Until finally, and suddenly, the job will finish despite never showing more than 0% complete. (NSProgress exists. Use it!)
/rant over
The Google Photos app is guilty of this as well. Many, many times the app will report that an image or video cannot be uploaded. Occasionally there might be a vague message saying the item was “unsupported” – despite the fact that it’s just a regular image taken with my iPhone. Same as the 80,000 the app has previously uploaded for me. And that’s it. No details. No way to try again or learn more about what went wrong or what might be done about it. Just a mostly silent failure.
Last Fall, my wife’s phone stopped backing up completely. The Google Photos app would not attempt to backup any new photos she took beyond a certain date. Logout / login. Delete the app and reinstall. Nothing worked. And, of course, there were zero error messages or even any indication anything was wrong or failing. Finally, we wiped her phone clean, let iCloud sync her photos back to the device, and tried again. Only then did Google start backing up once more. The cause? The solution? I have no real idea.
Now, compare that to Amazon’s app.
Bless those engineers. Look at all those glorious progress bars and detailed status labels. And when something does go wrong?
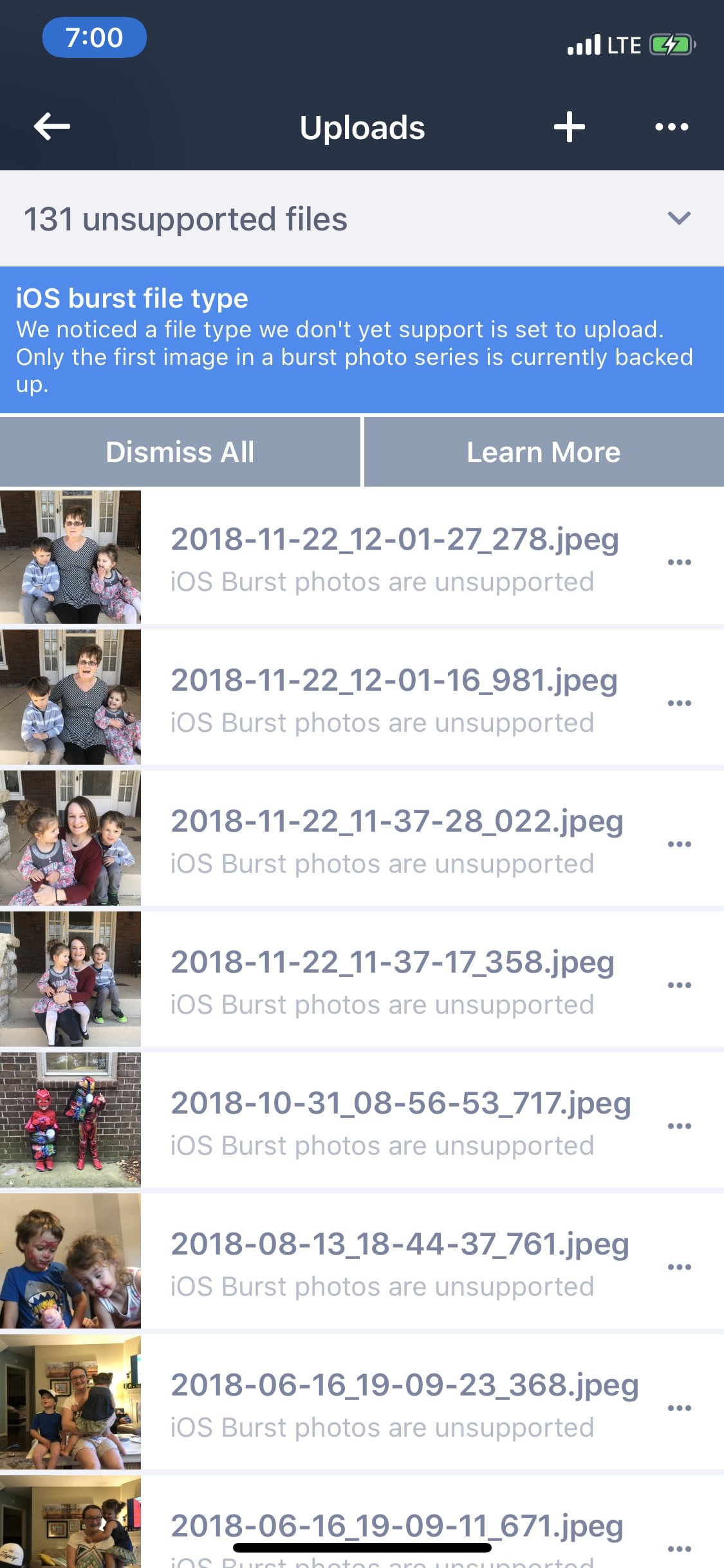
An actual error message with what went wrong! The product team that designed that screen would obviously never make it at a real Silicon Valley tech company.
Dealbreakers
With all the great things I said above about Amazon’s offering, why didn’t I stick with them? For a thousand paper cut reasons and one really big reason. First, here’s an email I sent to their feedback address.
Hi, Amazon folks.
I’m looking to move entirely away from Google Photos to Amazon. I’m really, really liking your product so far – especially being able to use the options on the left sidebar to explicitly filter combinations of people/places/dates. That’s a huge improvement over Google’s “only a search field” approach where I have to search and just hope Google figures out what I want.
I’ve successfully imported my 80,000 photos/videos from Google and recreated my 400+ albums. But there are a few key features that are preventing me from fully switching…
All of my albums follow the naming convention of “YYYY-MM Some Title”. For example “2019-06 Aaron’s 5th Birthday Party” or “2008-07 Beach Vacation”. This lets me sort by name and have them ordered chronologically. Unfortunately, in Amazon Photos I can’t search by album name. And with 400+ albums, that’s a huge problem.
Using the search field at the top of the page, I can enter a query and pause, and the search field will autocomplete and show a list of matching album names, but it’s extremely limited and not quite accurate enough. Here’s what I mean…
Say I have the following albums in my account:
* 2019-06 Aaron’s 5th Birthday Party
* 2019-06 Summer Camp
* 2019-01 New Year’s Party
* 2008-07 Beach Vacation
* etc
If I type “2019-06” into the search field and wait, it will correctly list the two matching albums. However, it will only display at most five results. If I have more matching album names than that, I can’t see them. If I actually perform the search (“2019-06”), the full search results page doesn’t list any matching albums – only individual photos ordered by date – no albums.
Also, going back to the search field, if I were to type “Party”, it doesn’t list any results despite there being (at least) two albums with the word “Party” in their names. It appears that the autocomplete results are only matching by the beginning of the album name – not by words within the full album name. And, again, even if the autocomplete results were more helpful, the full results page still isn’t returning results for albums.
Thanks for reading all the above. Your AI/ML based search results are a nice bonus feature for finding what I’m looking for, but for myself and the way I organize my family’s photo library, I really need to be able to do just a basic keyword search by album name.
Oh, and if it helps provide some weight behind my feedback: I’m a Prime member and also recently upgraded to an additional 1TB paid storage plan just for Amazon Photos. I’m sure my storage needs will continue to increase over time.
Happy to provide more detailed feedback if you have questions.
Cheers.
Tyler Hall
Even given that feedback, I was very much still on the fence. Until I hit a showstopper.
I have quite a few large videos in my library. They’re nothing insane. I’m not trying to upload blu-ray rips. But iOS now shoots video at 4k / 60fps. And I’ll occasionally take a 10+ minute home video. That’s easily multiple gigabytes in size. The Amazon iOS app handles files that size with no problems, but their server backend chokes.
I noticed this behavior with two videos – each 10 to 15 minutes long. Multiple days after uploading to their cloud, the website will show a thumbnail preview of the video, but it won’t play. Instead, it gives an error message saying the video cannot be played in a browser and I should use a mobile app instead. Ok, fine. But even on a stable wifi connection, those two videos would simply never play on any device. And I don’t mean they buffered or stuttered. Playback would just never start. Even if I dragged the scrubber to another point in the video, nothing. I tried again days later hoping that videos that big just needed extra time to process. But, the same result. I will say that I did try and download the raw video file and that worked fine. So my data was safe and backed up. It simply wasn’t viewable.
So, for me, that was a bug, breach of trust, a bridge too far, whatever you want to call it that made me realize I couldn’t fully switch to their product. At least not yet. But I’ll check back maybe in another year.
With Amazon out of the running, I still don’t know what I’m going to do when I hit Apple and Google’s next storage limit. But I estimate I have a least another 18 months before that becomes a problem.
Back to backing up my data – the whole point of this post. Here’s my solution.
My (Current) Google Photos Backup Strategy
I don’t trust Apple’s cloud. I don’t trust Google’s cloud. I don’t really trust anyone’s cloud for a number of reasons.
- When Apple does their best work, it’s often the best in the industry. But that’s becoming increasingly rare as the services we depend on become more and more complex, and, quite frankly, I’ve experienced enough bugs (worse – intermittent bugs) and poor product decisions that I’ve lost faith. They have my business, certainly, but they don’t have my trust.
- Even though I’m paying Google for extra storage space, I’m not their customer. I’m a product to be sold to their advertisers. And that puts me in a position where I have no leverage if something goes wrong. At any point one of their automated systems could flag me for a TOS violation and my account would simply be gone along with my data. It happened to my original Yahoo! account. It happened to my Twitter Developer account. It’s one of the main reasons why I quit Gmail years ago. And so I refuse to put all of my eggs in the basket of a company I can’t hold accountable.
- I don’t actually fear any cloud losing my data due to a hardware failure. My worries all revolve around an application error or process failure. I’m in love with the benefits our new services culture offers, but I don’t trust the system for a moment. If I don’t have a backup of my data under my control, then it may as well not exist.
I also don’t trust that my house won’t burn down. And my photos and videos are too precious to me to take a chance with. So, I want them in three places at all times:
- In Google Photos where they’re useable.
- Locally on an external backup drive at my house where they’re accessible.
- In Backblaze B2 storage where they’re safe in the event of disaster.
Google Photos should be the source of truth. It’s where my photos go first and how I organize them. B2 and my local copy should be a mirror of that and of each other.
If performing these backups becomes too time consuming or tedious, it won’t get done. And if you don’t have regular backups, why have any at all? And because each backup set might involve tens of gigabytes of new data, the whole process needs to be manageable from a 200 Mb/s Comcast Business connection. That’s the fastest internet I reasonably have access to.
So, every month on the 5th, I backup the previous month’s worth of photos and videos. Why the 5th day of the month? To stay organized, I literally only operate on and worry about days 1 – 30 of the previous month. By waiting to the 5th I can be reasonably sure of and notice if any stragglers from mine or my wife’s phones didn’t get uploaded.
The first step is to use Google Takeout to request a backup of my data. Doing a full Google Photos dump each month would be insane. Instead, Google helpfully allows you to choose specific albums and/or dates to archive.
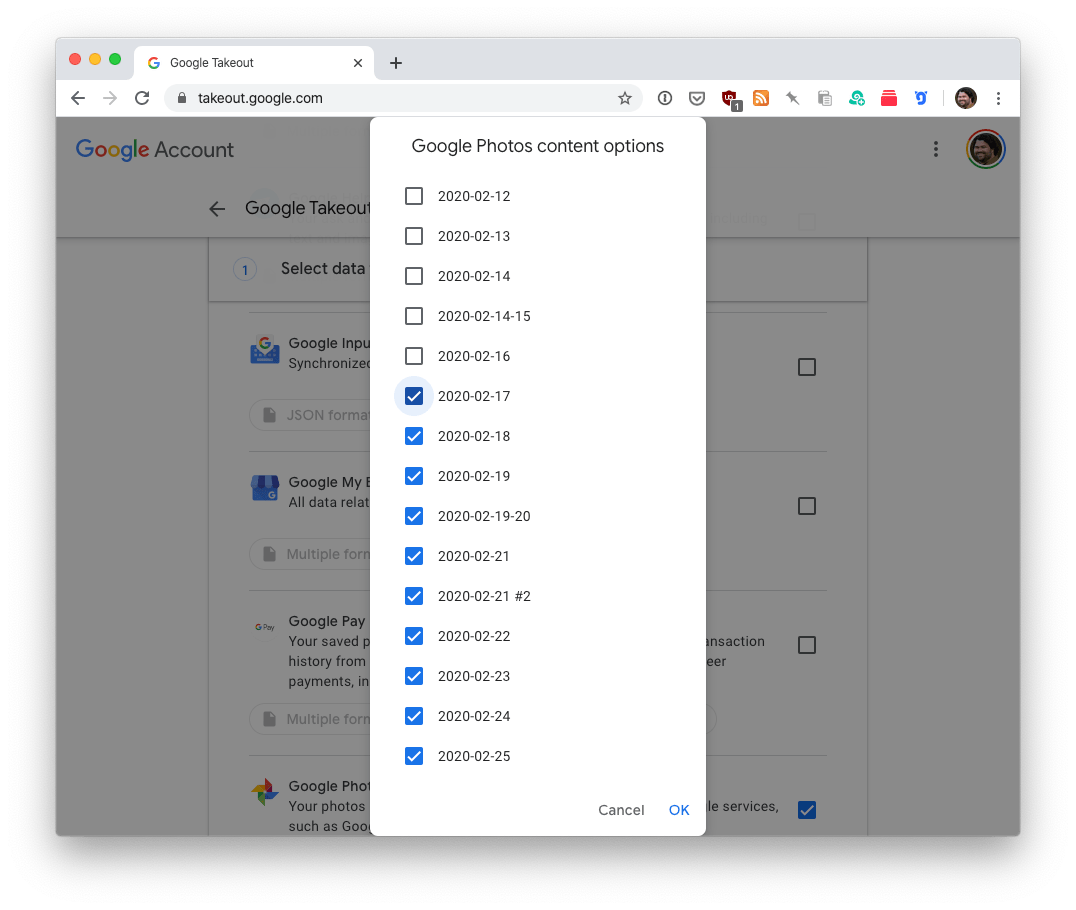
Request the backup, and then a few hours or maybe a day or two later, Google will email you when your data is ready. For reference, here’s the February 2020 backup I requested a few days ago:
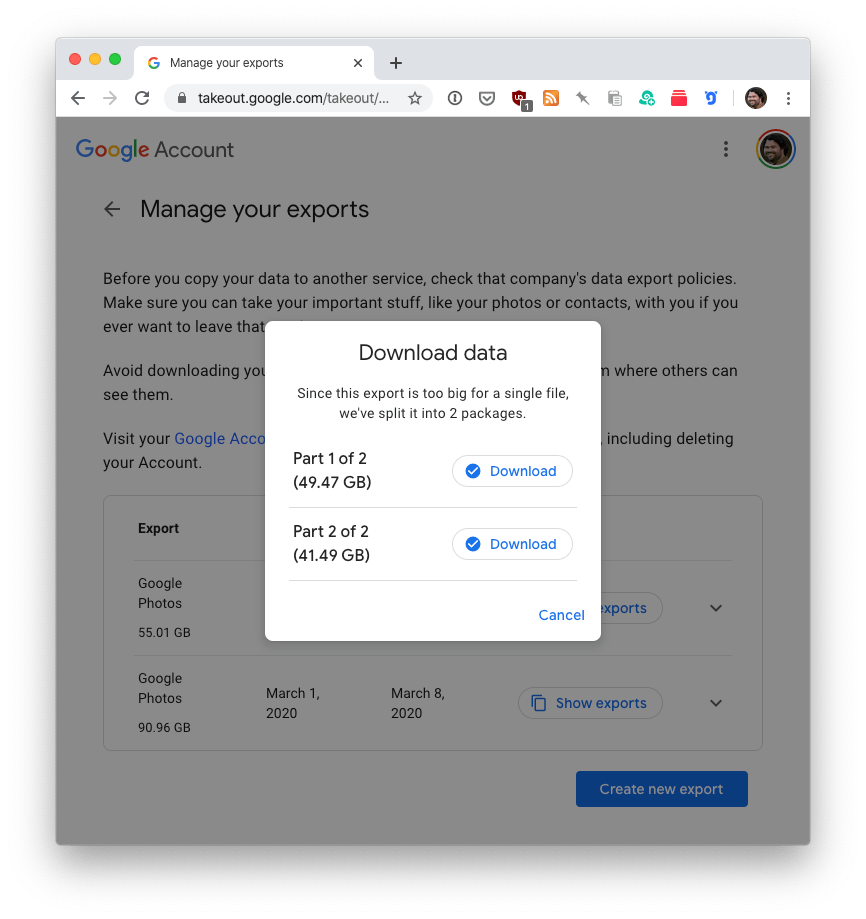
You’re seeing that correctly. My February archive was too big for a single 50GB .tgz file. So, Google helpfully split it into two. Ooof.
As I said above, I’m on a Comcast Business connection, so my download speeds are perfectly adequate. But it’s not fiber. And once I download 100GB and store it locally, I still then have to re-upload to B2. And my upload speeds are abysmal. So that’s out. Instead, I work around the bandwidth constraints like this.
I spin up a Linode (or DigitalOcean depending on my mood) VPS with just enough storage. For last month’s 100GB export, I went with an $80/month Linode that includes 320GB of storage. (Think: 100GB across two .tgz files and then double that once they’re extracted.) Don’t lose your mind yet. This whole process only takes an hour or two. So that $80/month price actually works out to less than $0.30 for the short amount of time I need it.
With plenty of storage and a fast cloud connection (I make sure to spin up the VPS in a California location since that’s where B2’s datacenter is), I download the Google Takeout archives remotely, extract, and sync to B2.
But wait! If you go this route you’ll find that the download URLs Google provides are protected behind your Google Account (as they should be). And since I’m doing all of this over an SSH connection to my VPS, I can’t exactly just give them to curl to do its thing. I’ll be unauthenticated and get rejected.
I toyed with various idea for how to login or spoof cookies or something, but I finally landed on a much simpler and more pragmatic solution. Using Charles Proxy as an SSL man-in-the-middle, I use Safari on my Mac to begin the download. Then, I kill it. Go to Charles and find that failed connection, right-click, and Copy cURL Request.
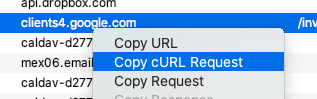
That literally puts the correct curl command on my clipboard including all of Google’s insane HTTP headers and authentication cookies. I can then just paste that into my shell and watch a 50GB file download in a matter of minutes.
Next, I extract the file, and use B2’s official command line tool to sync the new photos and videos into my bucket. Going datacenter to datacenter, it never takes longer than twenty minutes. Once the transfer is complete, I run the sync command a couple more times just to verify and let it report back that all files were copied successfully. Only then do I delete my data and destroy the VPS. And like I said earlier, the machine is only alive for at most an hour or two. So the costs never exceed $0.50 – even including bandwidth charges.
Your milage will vary, of course, but here’s the basic commands I use on the VPS (recent Ubuntu flavor) to install the B2 command line tool, download from Google, and sync to Backblaze.
The final step is to get the new data back down locally to my external drive. I also use B2’s command line tool for that. I’m lucky that downloading a hundred gigs of data only takes an hour or so. Even still, and even if it took multiple days, my iMac is always online so I just start the job and let it run however long it takes.
Ok, the final, final step is only sorta related to all this. Because storage is insanely cheap now, I also keep complete backups of my iCloud photo library as well as my wife’s in B2. Doing this is easier than backing up Google Photos. We each have accounts on my iMac with Photos.app set to download the original files of all our media. Then, I just setup Arq to backup to B2 every day and forget about it. It’s purely done as an ultimate last-ditch recovery solution in the event of a real disaster or if I manage to corrupt my other backups.
Next Steps
So that’s basically it. Nearly 4,000 words just to explain the convoluted process and reasons for how I backup my photo library. If the past has taught me anything, it’s that this strategy is likely to change in the future as well. As the amount of data we generate increases, bandwidth speeds up, and cloud and local storage prices fall, I feel like we’re at or nearing an inflection point where I can’t even imagine what my needs will be in the near future – much less years from now when I hand over the family archives to my kids for safe keeping as my aging father recently did to me with his own decades’ worth of genealogy research.
In the near term, my open questions are what will happen when my family hits the 2TB iCloud max? Apple doesn’t even offer a higher tier to pay for. I know that eventually they’ll recalibrate and increase their storage as the average Mac and iOS customer consumes more data. But if (when) I hit that limit before they do? I don’t know what to do other than just erase my iCloud photo library and depend entirely on Google Photos.
And speaking of, we’re going to hit our current 2TB plan’s ceiling within two years. And it’s a helluva jump from paying $10 a month to $100. I guess I’ll just have to move to Amazon at that point regardless of any remaining showstoppers in their product. And when I do, I’ll be sure to write about and publish the command line tools I wrote in Swift to migrate my library from Google to Amazon.
A Final Anecdote
In the first half of this post, and indeed in many, many of my posts on this blog and on Twitter during the last year or so, I’ve bitched about Apple and how I (and many others) perceive their recent software quality. Bugs, lazy decision making, too many balls in the air, etc. Certainly I could have been kinder in many of my assessments, but I stand behind everything I’ve written.
That said, a quick anecdote that I haven’t ever mentioned publicly.
After my Catalina rant gained attention last October, an Apple executive personally reached out to me via email. While it wasn’t exactly like one of those fabled responses out of the blue from Steve Jobs, it was along those lines in spirit. Over the course of a weekend we had a good discussion about the state of the Mac, how customers, developers, and shareholders like myself perceive Apple’s attention to the platform, as well as how this executive viewed the company’s commitment to the Mac – both software and hardware.
We certainly didn’t see eye to eye on every topic, and I’m not entirely sure how much of what they said were their honest feelings versus what their obvious PR training allowed them to say. But, it was a productive conversation. And whether or not they thought I was full of shit (I usually am) they did genuinely listen and demonstrate that they cared. I know this because
- As our exchange was winding down, they setup a phone call between myself and an Apple engineering manager to do a deep dive into some of the technical points I brought up in my Catalina post and over email. That manager turned out to be incredibly smart, thoughtful, and willing to consider and debate every suggestion I had. Every interaction I’ve had with Apple engineers in the WWDC labs has been excellent. This was no different.
- During our emails, I mentioned my pet peeve from earlier in this post about the lack of visual feedback, progress indicators, and silent failures that have crept into macOS. I offered to make a quick screen recording and also put together some examples to illustrate my points. They said that would be great, and when I sent them a link to a nearly 1GB zip file of videos and annotated PDFs on a Saturday morning, they replied a few hours later that “I’ve forwarded it to the team and they’re already looking into”. Okay. That’s nice to say but obviously lip service. At least I thought it was until I thought to check my server logs on Monday and saw that the file had been downloaded by nearly twenty internal Apple IPs Saturday afternoon and Sunday morning.
My point with all of that is that I’m going to keep bitching on Twitter and on this blog whenever I see shortcomings in Apple’s software and when I don’t agree with the direction they’re moving. But I am going to try and be kinder to the people behind the products. Because I know they are listening (to all of us, not just dumb me). And because this person took the time to demonstrate they obviously care.