Last week I mentioned that I had been yelling about Apple a lot on here lately and was going to try and be more positive. But allow me one more thought before I shut up…
We went on vacation this past week. Before we left I updated my phone to iOS 12.3 – my wife remained on the previous version. (This is where you all collectively go “uh-oh”.)
Spent five days at a state park shooting tons of video of the kids swimming, hiking, fishing, playing with their grandparents, etc. Irreplaceable stuff.
Get home, back on WiFi, start uploading everything to iCloud and Google Photos. After an hour or two everything’s synced.
Problem: All videos, of any length, stutter, stall, and skip frames in both Photos.app (macOS) and Google Photos on every Mac I try. Completely unwatchable. Time to debug things.
I export the raw files out of Photos.app to Finder and try opening with QuickTime. Same problem. Next, I use Photos.app to import directly from my phone via USB. Still broken.
But they play fine on iOS, so I never noticed any problems while filming last week.
Investigate further. It’s only MY videos that are broken. Videos my wife took are fine. Remember: I’m on 12.3. She’s on whatever 12.2 release was before.
All those videos of my kids? Gone.
This is a core competency of iOS that should never, ever fucking break for any reason. Apple markets iPhone’s camera as a top selling point – if not THE selling point.
Lucky for me, I’m tech savvy enough to know about Image Capture.app buried inside macOS’s Utilities folder. So I give it one last try using that to transfer the corrupted videos manually off my phone and into Photos.app and Google Photos.
It works. My memories are safe.
But would a normal Apple customer have thought to try that? Would an Apple Genius have figured it out? (Assuming they could even get an appointment.)
No. They would have simply lost everything.
This is fucking inexcusable on Apple’s part. DO NOT fuck with me when it comes to my photo library.
Apple needs to get off their goddamned pedestal, stop hosting self-congratulatory Lady Gaga concerts, and fix their fucking QA process, years-old bugs, and keyboards.
On the bright side, while I may never be able to trust Apple again with my photos (or type vowels on their laptops), at least they’re about to roll out a new credit card and custom-branded television content.
I’m about four weeks in and already finding it incredibly useful in my day-to-day.
I’ve built many different apps over the years, thrown them against the wall, and excitedly watched which ones developed a following and which ones failed miserably.
Most of my apps have fallen into two categories. There are the ones that solve a personal need I face, that I can inform and direct with my own experiences. And there are those where I saw a market opportunity or just thought they might be fun to build.
Almost all of the ones in that second category have failed. Incoming!, Nottingham, Highwire. They each had their share of a few passionate and engaged users, but mostly were ignored. (The jury is still out on Triage.)
But that first category of apps? Those have flourished.
I was a web developer for ten years before I started building Mac apps. I know the industry well. And working at an agency meant I was juggling many different websites at once. I needed a faster/easier way to spin up local development environments, and that led to me creating VirtualHostX. Which, in turn, led to Hostbuddy and Hobo years later.
My core set of apps, as I think of them, found a wonderful niche among solo web designers and developers and the small companies they work for. And the apps have succeeded beyond my wildest dreams. From 2012 to 2014 they were my full time and only job.
But since their heyday in 2014, sales have steadily declined. A big part of that, I think, is because the world has moved on from the LAMP-based standards of 2004 – 2012. NGINX, NodeJS, etc. have led to a sea change. If it weren’t for WordPress’s continued dominance, I’m not sure if I’d have any more sales at all.
So, I’ve seen the writing on the wall for a few years now, and have been on the lookout for ways to branch out and diversify my app portfolio.
I’ve done some freelance jobs here and there, and tried a few newthings on my own, but nothing has taken off. And as I talked about earlier, I think a lot of that is due to none of those new ventures being true passion projects that I could bring my own experiences as a user with specific needs.
But four weeks ago I finally became fed-up with the awfulness of Mint.com. I know they’re able to provide a free service because they plaster the site with advertisements and sell my data, and I’d be ok with that if they weren’t so intrusive. But they’re taking over nearly the entire browser window now. Add to that the cumbersome Web 2.0 UI and lack of any real reporting capabilities, and I’d had enough.
What I really want is a fast, powerful, native Mac app that automatically imports my financial data and gives me the ability to slice, dice, filter, organize, and export my data in every possible way. The flexibility and power of an Excel sheet with the learning curve of iOS and the familiar paradigms of a real Mac app. Something that keeps me in control of my data, respects my privacy, and syncs to all my devices.
So I built it.
Most of it. It’s not done yet, but all the major pieces are in place, and I’m using it to track my family’s budget every day.
I’ve taken a heavy dose of inspiration from one of my favorites apps – OmniFocus – both from a UI perspective (a clean, modern, attractive Mac interface) and from the power they afford users over their data by way of custom perspectives.
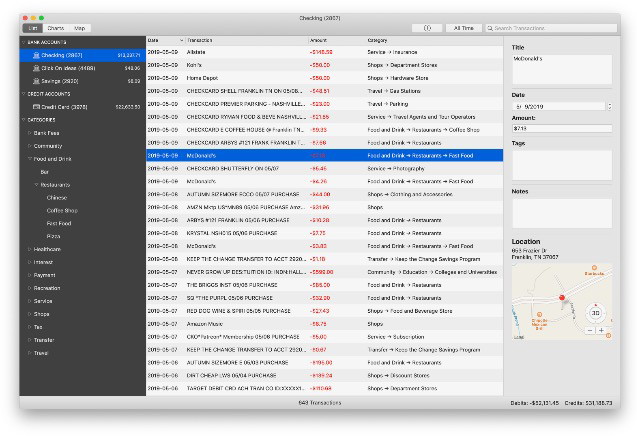
My app is smart. It auto-categorizes your transactions. You can just let the app do its thing and everything will end up in the (mostly) appropriate place. Or you can categorize each transaction manually. Or you can setup smart rules to do it for you automatically. Whatever fits your workflow.
Each transaction can belong to a single category. But categories can be nested. With one click you can see all the dining out you did last month. Or just the fast food orders. Or just what you spent at McDonalds.
And then there are tags. Assign multiple tags to a transaction. Do it manually, or create a smart rule to assign them automatically. Then use the app’s powerful search feature to find any combination of AND / OR.
Take search further by combining tags with categories and date based filtering. Find every Uber ride tagged #business during the last quarter and export the results to a CSV you can send to your boss to get reimbursed. Snapped a picture of the receipt with your iPhone? Yep, you can attach files, too.
And once you’ve got that perfect search query and set of filters in place, save it as a new Report that you can recall at any time. Just like an OmniFocus perspective.
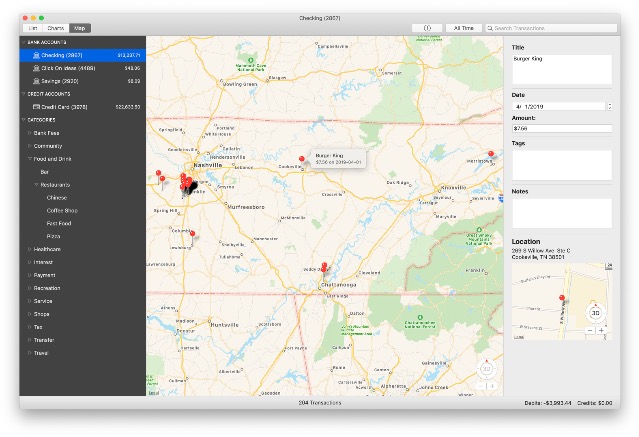
And, just for fun, why not view all of your transactions plotted on a map?
I’ve got all of this working (albeit without the necessary UI/UX polish) and it’s totally opened my eyes to some aspects of our financial situation that I’d overlooked. The last major piece is adding a budgeting component. I know the system I want to adhere to, but I’m still working through how it will fit in the interface.
Of course, I’m leaving out the iOS counterpart. But I’m saving that for later. The model layer is still a bit too much in flux. But I’ve written all the business logic to be platform agnostic. So the plan is to reimplement the appropriate features in UIKit (not everything the Mac app can do would make sense or be needed on a mobile device) and reuse as much of the existing codebase as possible.
But don’t forget syncing. As I said in my requirements, I want this app to be privacy-focused and have the user be in charge of their own data. So, no financial data will ever touch my server. Unless they enable syncing, no data will ever leave their device. But if they do want to sync, that’s all privately handled by CloudKit so I, the developer, can’t see their info even if I wanted to.
So, that’s it. That’s what I’ve built and am working towards completing. I have no idea when it will be ready. CloudKit could easily throw a big wrench into everything. And I’ve also got major updates to VirtualHostX and Hostbuddy underway and due out this Fall.
But I’m excited. It’s an app I’m passionate about and I have a clear direction and feature set in mind. It caters to a broader audience than my developer-focused products and could potentially save my tiny company if they continue to trend downwards.
Remember iTunes Match? It’s great. But Apple stopped promoting it (probably rightly so) a couple years ago when they realized they could make more money charging $10/month for Apple Music than Match’s $25/year.
Anyway, I loved it and still do. It uploads all of your digital music to Apple’s cloud and makes it streamable on all of your devices. And I mean all of it – especially your ripped mp3s, live albums, or anything else not in the iTunes Store. And if they can “match” any of those unofficial mp3s to a song from the store, they’ll “upgrade” you to the higher-quality AAC file for free. I had thousands of low quality mp3s ripped in the early 2000’s and late 90’s. Now they’re metadata tagged appropriately, with artwork, and sound better.
When I first joined iTunes Match (seven?) years ago, I uploaded all my music, made a backup of my local library, deleted everything, and just streamed from then on to save hard drive space.
As I acquired new music, it went to Apple’s cloud, but I never got around to backing it up offline.
As I’ve been writing about this month, I’m re-evaluating my backups strategy. This week I got around to looking at my music collection and decided it was time to retire that old external drive and put everything in B2 – around 300GB.
Knowing that drive was out of date, I figured I’d just download a fresh, complete copy from Apple.
I selected everything in iTunes, and clicked the download button. And waited.
The next morning I found my nearly 25,000 tracks stored locally – and a ton of errors.
Out of the 25,000, nearly 1,500 had failed to download and reported all sorts of various network errors.
I made a quick smart playlist showing all songs in the cloud but not available locally. This made it easy to isolate the problem items.
I tried downloading all the missing songs, but each one failed again. So I tried downloading a few individually with no luck. You can see where this is going.
After much testing and troubleshooting these 1,500 songs (all from various albums, some from ripped CD’s, some purchased from the iTunes Store) are seemingly gone.
It’s not the end of the world. If I really want some of them, I’m sure I could just re-purchase or stream from Apple Music. But others, especially some amazing live albums I collected in college are gone.
So I uploaded what I had to B2. And then made a csv export of the playlist of missing songs for good measure.
And while I love and take advantage of the cloud’s convenience, this is why I don’t trust my data to be in only one place. It’s my fault for not backing up this part of my data if it was important to me. It’s the first real data loss I’ve experienced in years – maybe since 2010. Maybe it’s just a bug that Apple will eventually fix.
I’ve been hosting my company‘s email with FastMail since 2008. They’re amazing. But my personal email had been with Gmail since the service was in beta in 2004. (And everything before Gmail lost to time and bit rot. Sigh.)
Around five years ago, I started getting nervous with so much of my online identity tied to an address that I was essentially borrowing and had no real control over. I was never worried about Google losing any of my data, but I had heard countless horror stories of Google’s AI flagging an account for some type of violation and locking out the user with no recourse.
If I ever lost access to my primary email account, I’d be dead.
So I began the rather annoying process of moving all of my online accounts over to use a new address at a domain I control. FastMail imported everything from my old Gmail and Google Calendar account, and with the help of 1Password, I was able to methodically switch my email everywhere else over the course of a few weeks.
I’ve been using my new address full-time for the last five years and now get only two or three non-spam emails a month to my old Gmail account.
Soon after switching emails, I began to question my other dependencies on Google. Along with Facebook, I started worrying about all the data they were collecting on me. I was also concerned about how I was playing a part in their monopoly over the web as a whole.
So I switched to using Duck.com as my full-time search engine. And I gave up Chrome in favor of Firefox. I even tried using Apple Maps as much as possible. In short, even if the alternative service wasn’t on par with their bigger competitor, I felt it was worthwhile to give them my support to encourage a more balanced ecosystem.
The switch mostly went well. I felt like the search results I got with Duck.com were good enough. I only had to fall back to Google for the occasional technical query. Firefox also made great strides with its support for macOS during that time with their Quantum project. And Apple Maps, despite all the awful reviews online, worked just fine navigating around Nashville for me.
But over the last year I’ve started, slowly, coming back to Google’s services.
It all started with Google Photos. I (mostly with the help of my own backup strategies) trust iCloud with my family’s photo archives. But Apple just makes it too inconvenient to use with a partner. Because of the way iCloud is siloed per user, my library is completely walled off from my wife’s. That means I can’t see photos of my kids that she takes. And she can’t see mine. Google Photos supports connecting your library with another person’s. (While that’s a super useful feature, we don’t do that. For our workflow, it’s easier just to sign into my Google account in Google Photos on my wife’s phone so everything funnels into one primary account.)
And while Apple’s Photos.app AI-powered search is mostly-good, it’s limited by their privacy stance and what they can process on-device. And the result is that it can’t even begin to compete with the ways I’m able to slice, dice, sort, and organize my photos with Google.
Is Google using the faces and location data in my photos to train their robot overlords? Most definitely. Do I care? Yes. But is it enough to outweigh the benefits I get from their otherwise amazing offering that I pay $10/month for? For me, no.
Added to that is the degradation in quality I’ve seen in Duck.com’s search results since last year. I’m not sure what changed under-the-hood, but I found myself having to search a second time in Google way more frequently to the point where I just gave up and made Google my default choice in January.
I’ve been a paying customer of Dropbox since 2008 (or 2009?). But because of the $10/month I was paying Google for extra photo storage space (2TB) (which I get to share with my wife’s Google account), and the $10/month I pay for extra iCloud storage (which I also get to share with my wife), it just didn’t make sense to keep paying for Dropbox as well when I could use Drive instead. And you know what? After using Drive for the last six months I’ve found that it’s really quite nice. Especially with the added benefits of everything integrating with Docs and Spreadsheets and their very capable (but decidedly non-iOS and ugly!) mobile apps.
Further, although not really that important, I’ve also migrated my calendars from FastMail back to Google Calendar simply because every other service in the world that wants to integrate with my calendar data (and that I want to give permission to) supports Google’s protocol but not standard CalDAV. It’s a shame, but I’ve decided to make my life easier and just go with it than wall myself off by taking a principled stand for open data.
What does this all mean?
I still use Firefox. I stick with Apple Maps when possible. But I’ve slowly moved back to Google’s services in cases where they’re so far ahead of the competition I just can’t help it, which has created a bit of a halo-effect with their complimentary services.
And in a most-decidedly un-Googly turn of events, customers of their Google One extra-storage plans can now talk to a Real Live Human if something goes wrong. That gives me much more confidence in my precious data’s longevity with them, which is what drove me away from Gmail in the first place.
Dammit, Google. I don’t trust you. But I can’t quit you, either.
A couple weeks ago I wrote about how I was automatically capturing the photos and videos my kids’ daycare emails to me and importing them into Photos.app. The major pieces of that script worked fine – parsing the emails, downloading the images, and then rsync’ing them down to my Mac every hour.
But what was failing was the Finder Folder Action I setup that was supposed to import the files into Photos.app whenever new ones were added to that folder.
For some reason, the Folder Action would only occasionally fire. Maybe for one out of every ten items. Sometimes, if I navigated to the folder in the Finder, the action would kick-in and import everything. But sometimes not.
All I can think is that because the files were being added to the folder via rsync – using some BSD-like filesystem APIs instead of the higher-level macOS ones – the Folder Action was never being triggered. Again, it occasionally worked, but mostly failed. So I could be entirely wrong about all of this.
Anyway, I rewrote the whole thing to just run an AppleScript every hour via cron, which handles the whole process itself. Since making that change it’s been working perfectly.
Just a quick note for my future self and anyone else who might be running into this problem.
Last week I migrated all of my backups off of Amazon S3 and rsync.net to Backblaze B2. The cost savings are enormous – especially for a small business like myself. And the server-to-server transfer speeds using their b2 Python script, while not as fast as using a raw rsync connection, are quite a bit quicker than using S3.
Before committing to B2, I gave it a really thorough test by seeding it with 350,000 files totaling 450GB. The whole process took about eight hours coming from my primary Linode server in Atlanta. I was quite pleased.
Anyway, after testing all of my scripts, I put them into cron and ignored them for the next few days assuming they’d “just work”. But when I went back to check on them, I found every one had been failing silently.
At first I thought maybe the b2 command wasn’t found in $PATH when running via cron for some reason, but that wasn’t it. Next I double-checked that b2 was using the correct credentials I had previously authorized it with by hand. Nope.
Turns out, b2 was throwing this Python exception.
Creating a Pipfile for this project...
Creating a virtualenv for this project...
Traceback (most recent call last):
File "/usr/local/bin/pew", line 7, in <module>
from pew.pew import pew
File "/usr/local/lib/python2.7/site-packages/pew/__init__.py", line 11, in <module>
from . import pew
File "/usr/local/lib/python2.7/site-packages/pew/pew.py", line 36, in <module>
from pew._utils import (check_call, invoke, expandpath, own, env_bin_dir,
File "/usr/local/lib/python2.7/site-packages/pew/_utils.py", line 22, in <module>
encoding = locale.getlocale()[1] or 'ascii'
File "/usr/local/Cellar/python/2.7.13/Frameworks/Python.framework/Versions/2.7/lib/python2.7/locale.py", line 564, in getlocale
return _parse_localename(localename)
File "/usr/local/Cellar/python/2.7.13/Frameworks/Python.framework/Versions/2.7/lib/python2.7/locale.py", line 477, in _parse_localename
raise ValueError, 'unknown locale: %s' % localename
ValueError: unknown locale: UTF-8
I’m hardly a Python expert, and I’ve traditionally had nothing but problems anytime I’ve had to do anything with pip, so this didn’t surprise me. What did surprise me was that this error was happening both locally on my Mac (10.14.4) and on my remote Ubuntu 18.04 box.
After some googling I found this bug in pipenv. The solution is to add the following to your b2 scripts that are run by cron:
export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8
And that fixed it.
I know macOS ships with a mostly-broken installation of Python, but the latest Ubuntu LTS? Anyway, if this is common Python/pip knowledge, at least now I know, too.
This allows you to create multiple tasks in OmniFocus with defer dates, due dates, and tags in one step.
It does this by parsing a compact, easy-to-write syntax that I’ve adopted from other OmniFocus actions and tweaked to my liking and then converting it into TaskPaper format, which can be “pasted” into OmniFocus in one go. This removes the need to confirm each individual action separately.
Yes, you could also do this by writing your tasks in TaskPaper format directly, but I find its syntax (while innovative!) a bit cumbersome for quick entry. The format this action uses isn’t as feature-rich, but it does everything I need and with less typing.
Instructions:
Each line in your draft becomes a new task in OmniFocus, with the exception of “global” tags and dates, which I’ll describe later.
Each task goes on its own line and looks like this:
Some task title @defer-date !due-date #tag1 #tag2 --An optional note
The defer date, due date, tags, and note are all optional. If you use them, the only requirement is that they come AFTER the task’s title and the “note contents” must be LAST.
The defer and due dates support any syntax/format that OmniFocus can parse. This means you can write them as @today, @tomorrow, @3d, @5w, etc. If you want to use a date format that includes characters other than letters, numbers, and a dash (-), you’ll need to enclose it in parenthesis like this: @(May 5, 2019) or !(6/21/2020).
Global Defer/Due Dates:
By default, tasks will only be assigned defer/due dates that are on the same line as the task title. However, if you add a new line that begins with a @ or ! then that defer or due date will be applied to ALL tasks without their own explicitly assigned date.
Global Tags:
Similarly, if you create a new line with a #, then that tag will be added to ALL tasks. If a task already has tags assigned to it, then the global tag(s) will be combined with the other tags.
Full Featured (and contrived) Example:
Write presentation !Friday #work
Research Mother's Day gifts @1w !(5/12/2019) --Flowers are boring
Asparagus #shopping
#personal
@2d
You can install the action into your own Drafts.app from the action directory.
Drafts is my preferred way of capturing text and ideas on Mac and iOS and then doing something with it. It has tons of scripts (actions) to do just about anything, and you can write your own if you need something custom.
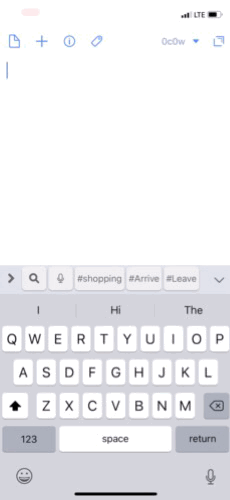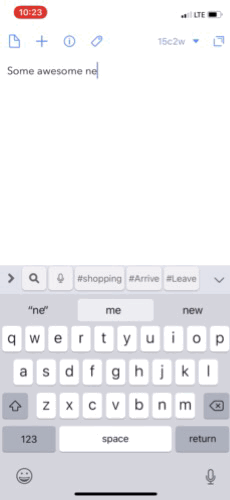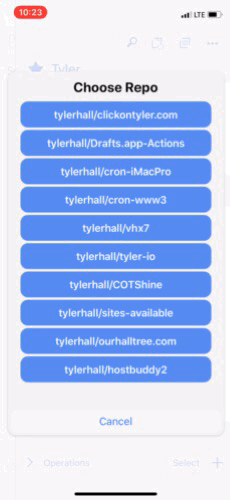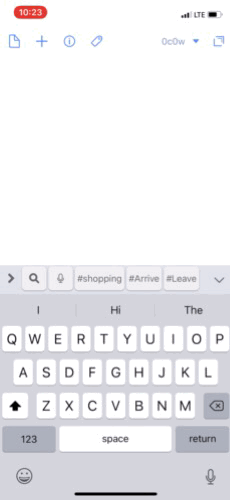
So, after a quick look through GitHub’s API docs, I put together this script for Drafts.
It fetches your most recently active repos, presents them in a dialog prompt to pick one, and then creates a new issue in that repo using the contents of the current draft. Simple. Fast. Awesome. And a lot easier than trying to navigate GitHub’s mobile website.
You can install the action into your own Drafts.app from the action directory.
In my quest to backup ALL THE THINGS, I turned my attention earlier this week to the shared iCloud Photo Albums my friends and family use to pass around photos and videos of our kids.
All of the items in my iCloud library (and my wife’s library) are combined and backed up to Google Photos automatically. For better or worse, Google Photos is the “source of truth” that contains all of our archives and is sorted into albums. It’s the backup I’d use to restore if iCloud ever goes belly-up. (And I have a redundant backup of Google Photos itself in case Google ever loses my data.) And the actual Photos.app library on my iMac is backed up to Backblaze for good measure, too. So the photos we take are covered.
But there are a ton of great memories of our kids snapped by other people. Those only reside in the shared iCloud photo streams. How do I back those up?
Ideally, Photos.app on Mac (or iOS) would have a preference to automatically import shared items taken by other people – and then those would feed into Google Photos. But that doesn’t exist. I could manually save-to-my-library new items as they’re shared, but that’s error prone and not scalable.
Also, what about the 2,000+ previously shared photos? I thought I would be clever and just select-all on my Mac and drag them into my main library, but after doing a few quick tests I realized Photos.app isn’t smart enough to not duplicate the photos I took and shared when importing. (This is likely due to Apple scaling-down and stripping out metadata of shared items.) And there’s no way to sort by “other people” or build a smart album of “photos taken by other people” to filter out your own images when importing.
So, I decided to do some digging.
The first step was to locate the shared albums on disk. I searched my main Photos Library.photoslibrary bundle, but couldn’t find them inside. A quick glance through ~/Application Support/ didn’t turn up any obvious hiding places either. That’s when I fired up DaisyDisk to search for large (10GB+) folders.
Success!
For my own reference and for anyone else who comes across this post after googling unsuccessfully, iCloud’s shared photo albums are stored here:
Each shared album is inside that folder and given a UUID-based folder name. And inside each album, every shared photo/video is itself inside its own UUID folder name. It’s quite impenetrable and obviously not meant for users to poke around, but the programmer in me understands why it is this way.
At the top level is a Core Data database. I thought I might get clever and explore that to see if I could extract out the metadata of the shared items and use it to help me write a “smart” backup script (that perhaps imports other people’s photos directly into Photos.app) instead of just taking the brute-force approach and backing up the entire album as a dumb blob, but I haven’t had enough time yet to investigate.
So until I find the time to build that “smart” approach, I’m going about it the dumb way and nightly syncing everything to B2. It’s not ideal, but it covers my needs for now.
I’m very meticulous about logging all of the feedback I receive from my customers. Whether it’s a bug report or a feature request, I want all of that information captured in a single place where I can plan and act on it. For me, that place is the Issues section in my app’s GitHub repo.
Normally, when I get a customer email, my workflow is to reply back to them with any clarification I need, and then once we’ve finished with any back and forth, create a new GitHub issue with the relevant info from their email and a note reminding me to email them back when their issue is resolved.
This takes all of a minute to do. But it still means opening a browser, navigating to the repo, clicking on “Issues”, then “New Issue”, and copy and paste the email details. Further, if the user supplied any screenshots, I have to save those out of the email and upload them to GitHub as well. Like I said, it only takes a minute or so, but it adds unnecessary friction.
Today I decided to automate all of that.
I use the fantastic Postmark service to send all of my company‘s transactional emails. They also have an equally awesome inbound service that will parse any emails you forward to them and POST the details as a JSON blob to your web hook.
Postmark receives the forwarded email and POSTs the data to my server, which runs a small PHP script (embedded below) that downloads any image attachments contained in the email and creates a new GitHub issue in the appropriate repo with the contents of the email and image attachments.
It all works great! What used to be a slightly annoying process to do a couple times a day, now takes all of three seconds in my email client – whether I’m at my desktop or out and about on my phone.